컴퓨터 아키텍쳐에서 배운 CPU, Memory, Storage, Network로 이루어진 Hardware 위에 운영체제(OS)가 탑재되어 있고, 이 운영체제는 시스템 콜을 바탕으로 작동합니다. 이 위에는 각 프로그래밍 언어를 컴파일하는 컴파일러와 라이브러리/API가 있으며, 그 위에 사용자와 컴퓨터의 Interaction을 담당하는 Shell 및 Editor가 있습니다.
즉, 사용자가 Shell이나 Editor를 통해 작성한 응용프로그램은, 컴파일러를 통해 번역되어 필요한 작업을 시스템 콜을 통하여 OS에 요청하게 됩니다.
그럼 구성요소 각각에 대해서 조금 더 알아보겠습니다.
1. Shell : 사용자가 운영체제 기능과 서비스를 조작할 수 있도록 하는 인터페이스
*CLI / GUI 두가지 방식이 있다.
2. API : 라이브러리 혹은 함수의 모음집
3. 컴파일러 : 사용자가 작성한 코드를 컴퓨터가 이해할 수 있는 언어로 번역하는 시스템
4. 시스템 콜(시스템 호출 인터페이스): 사용자가 원하는 작업을 OS에 요청하는 방식
5. 운영체제 : 리눅스, 윈도우 같은 컴퓨터 자원 관리 및 사용자 요청 작업을 수행하는 프로그램
이제 본격적으로 운영체제에 대하여 알아보겠습니다.
사용자가 작성한 응용 프로그램은 CPU에서 원하는 작업을 수행하게 되는데, 이 때 직접 수행 가능한 것이 있고 반드시 시스템 콜을 거쳐서 작업을 수행해야만 하는 것이 있습니다. 시스템 콜을 통해서만 수행할 수 있는 영역은 커널 영역(모드)라고 하고, 그렇지 않은 영역을 사용자 영역(모드)라고 합니다. 이러한 영역은 CPU Protection Ring으로 아래와 같이 구체화되어 있습니다. 사용자 모드/커널 모드로 구분하여 권한을 부여함으로써, 컴퓨터는 임의의 사용자가 함부로 컴퓨터의 운영체제를 손상하는 것을 막을 수 있습니다.
다음 글에서는 컴퓨터 구조의 구성요소들을 컴퓨터가 어떻게 활용하고 분배하는지, 프로세스와 스케쥴링에 대해 알아보도록 하겠습니다 -!
3.1) 스택 : 지역변수를 선언하는 공간으로 정적으로 공간이 할당됩니다. 프로그램 종료 시 자동으로 소멸됩니다.
3.2) 힙 : 동적으로 할당된 메모리 영역으로, 개발자가 직접 해제해줘야 합니다.(자동 소멸 X)
4) 데이터 패스 : 데이터의 이동 경로
5) 제어 유닛 : 컴퓨터의 실행을 제어하는 역할
예를 들어 CPU 같은 프로세서는 (데이터 패스) + (제어 유닛)으로 나타낼 수 있습니다.(레지스터같은 약간의 메모리도 가지고 있죠) 제어 유닛에서 제어 신호를 생성하여 순서대로 명령을 실행하게 되는데, 명령어가 주어지면 ALU에서 연산을 수행하고 이 수행 과정에서의 데이터가 레지스터에 저장됩니다.
* 메모리 계층구조
: 속도가 빠른 메모리는 비싸기 때문에, 컴퓨터의 메모리는 서로 다른 속도와 크기를 갖는 여러 계층의 메모리로 구성되어 있습니다.
속도 : 레지스터 > 캐쉬 > 램 > SDD > HDD
위와 같은 순서로 속도가 빠르게 되며, 빠를수록 가격이 비싸기 때문에 용량이 작고, 자주 사용되는 메모리입니다.
2. 기계어, 어셈블리어, 고급 언어
우리가 일반적으로 아는 C, Java, Python 과 같은 언어는 고급언어라고 불립니다. 인간이 이해하기 쉽고, 인간에 의해 작성된 알고리즘이 컴퓨터를 제어하게 됩니다. 일반 사람들도 코드만 보고는 이해하기 어려운 알고리즘을 컴퓨터는 어떻게 이해하고 작업을 수행하는걸까요?
우리가 고급 언어로 작성한 알고리즘은 컴파일러에 의해 어셈블리어로 변환되고, 어셈블리어는 다시 기계어로 변환됩니다. 이 때 기계어는 0과 1만의 조합으로 나타내지게 되어, 컴퓨터는 이를 수행할 수 있습니다.
어셈블리어에 대해 조금 더 공부해보면, 어셈블리어는 아래와 같이 opcode(실행코드), operand(실행코드)로 구성되어 있습니다. opcode에는 ADD, BRANCH 같은 명령어를 넣고, ADDRESS는 해당 연산을 수행할 공간(변수 혹은 주소의 절대값)을 입력하게 됩니다. 우리가 C언어로 작성하는 코드들은 컴파일러를 통해 이런 명령어들로 변환되게 됩니다.
http://egloos.zum.com/dreamform/v/2805479
3. 컴퓨터의 성능과 전력
우리는 영상이나 인터넷 서핑 등 다양한 목적을 위해 컴퓨터를 구매합니다. 이런 다양한 목적을 수행하는데 걸리는 시간이 짧아질수록 시간은 절약되기 때문에, 우리는 컴퓨터의 성능(과 가격)을 고려하여 구매를 결정합니다. 가격이 높을수록 컴퓨터의 성능은 좋아지겠지만, 컴퓨터의 성능이란 것은 무엇일까요?
컴퓨터의 성능을 평가하는 다양한 지표가 있지만, 대표적으로 응답시간과 처리량을 바탕으로 평가합니다. 응답 시간은 특정 작업을 수행하는데 걸리는 시간이며, 처리량은 단위시간 내에 처리할 수 있는 작업의 양을 뜻합니다. 응답 시간과 처리량은 일반적으로 반비례하며, 짧은 시간 안에 최대한 많은 작업을 처리하는 컴퓨터의 성능이 좋다고 말합니다. 그렇다면 이런 응답 시간과 처리량은 어떤 기준으로 평가할 수 있을까요?
컴퓨터는 우리에게 시간과 같은 개념으로 클럭이란 개념을 가지고 있습니다. 클럭이란 아래와 같은 일정 주기를 가지고 0과 1을 왔다갔다하는 신호를 말합니다. 이 신호가 1이나 0에 이를 때, 컴퓨터는 특정 작업의 수행을 시작할 수 있습니다. 예를 들어, Clock이 High(1)이 되면 작업을 수행하고, 작업이 끝나면 대기하다가 다른 작업이 들어오면 다음 클럭이 High(1)이 될 때 작업을 시작합니다. 즉, 클럭이란 컴퓨터가 작업을 수행하는 최소 단위(시간)이 되는 것이죠.
클럭의 속도가 높아질수록 컴퓨터는 시간을 더 잘게 쪼개서 작업을 수행할 수 있게 되어, 짧은 시간 안에 더 많은 작업을 수행할 수 있습니다. 하지만 클럭이 높아지면 높아질수록 소비전력과 발열량이 늘어나게 됩니다. 클럭 또한 트랜지스터의 작동으로 인해 생성되는 것인데, 소비전력은 트랜지스터의 스위칭 횟수에 비례하기 때문입니다. 더 많은 스위칭이 일어날수록 소비하는 전력과 발열량은 늘어나게 됩니다. 따라서 클럭의 수는 일정하게 유지하는 동시에, 코어의 수를 늘려 전력을 낮추는 방법을 사용하여 CPU는 발전해왔습니다.
클럭이 동일하더라도 CPU의 개수를 늘려서, 여러개의 CPU에서 병렬적으로 작업을 수행하면 속도는 더욱 빨라지겠죠. 하지만 병렬화도 최적화되지 않으면 싱글코어나 다름없기 때문에, 이 병렬화 작업을 최적화해주는 작업은 매우 어렵다고 합니다.
이렇게 발전해나가는 CPU들 중 우리가 많이 들어본 i3, i5, i7에 대해서 알아보겠습니다.
[ i3 - 2코어 4스레드]
[ i5 - 4코어 4스레드]
[ i7 - 4코어 8스레드]
위와 같이 구성되어 있다고 합니다. 스레드(Thread)는 프로그램을 구성하는 최소 단위로, 나중에 더 자세히 알아보도록 하겠습니다. i3가 싸고 i7이 비싼 것은 , 코어 수와 스레드 수가 증가함에 따라 병렬화하여 작업을 더 효율적으로/빠르게 처리할 수 있기 때문입니다.
4. 컴퓨터의 연산
위의 내용들을 바탕으로 컴퓨터는 덧셈/뺄샘 등의 연산을 진행하게 되는데, 특이한 소수점 연산에 대해 알아보기로 하겠습니다. 소수점을 계산하는 방법은 아래와 같은 두 가지 방법이 있으며, 일반적으로 부동소수점 방식이 사용됩니다.
저는 [데이터 분석 입문 - 올인원 패키지] 의 내용을 아래와 같이 세 가지로 요약해보았습니다.
#1 데이터 분석은 무엇이고 이와 관련된 직업에는 무엇이 있을까?
#2 머신러닝 및 딥러닝이란 무엇이고, 데이터 분석에는 어떻게 사용되는가?
#3 기초 통계 상식 및 분석 방법
#4 실습
#1 데이터 분석은 무엇이고 이와 관련된 직업에는 무엇이 있을까?
1. 데이터 분석 정리 및 필요성
: 데이터 분석은 기술통계 및 시각화, 통계적 추론을 통하여 데이터에서 의사결정에 기반이 되는 INSIGHT를 얻어내는 과정이다. 데이터 분석은 아래와 같은 절차들을 거치게 되는데, 데이터 엔지니어, 데이터 분석가, 데이터 사이언티스트가 아래의 작업들을 나누어 수행하게 됩니다.(큰 회
사일수록 일이 더 세분화가 되어있을 확률이 높습니다.)
* 데이터 엔지니어 : 분석에 필요한 데이터 추출, 정제 등을 담당하는 직업이다. 데이터 파이프라인 설계, 데이터 웨어하우스 설계 등의 업무를 담당한다.
* 데이터 분석가 : 데이터들을 기반으로 분석 계획 및 가설을 세우고 가설 검증을 진행하는 직업이다. 분석 주제 발굴 및 데이터 모델링 등의 업무를 수행한다.
* 데이터 사이언티스트 : 데이터 분석가와 업무의 롤은 비슷하지만, 범위가 더 넓다. 빅데이터 처리 경험과 딥러닝 활용법들을 숙지하고, 기존 분석 방법에 더불어 활용할 수 있어야 한다.
위와 같은 데이터 분석 과정은 현업에서 다양한 방법으로 활용되고 있고, 데이터의 양적인 성장에 따라 중요성은 점점 더 강조되고 있습니다. 활용 사례들은 아래와 같습니다.
1) 현업에서의 데이터 분석 사례 :공공데이터 공공데이터는 환경, 수출 등 무수히 많은 데이터가 축적되고 있고,data.go.kr과 같은 사이트에서찾아볼 수 있습니다.
2) 현업에서의 데이터 분석 사례 : 제조업 제조업 데이터는 경우 변수 개수가 상당히 많습니다. 제조 공정별로 변수가 여러가지가 생성되기 때문에 중요 변수들을 잘 추출하여 분석하는 능력이 중요합니다.
1) 다중공선성 : 독립변수들간에 높은 선형관계가 존재하는 경우를 뜻하는 말로, 다중공선성이 높은 경우에는 변수를 적절히 제거할 필요가 있습니다. 2) 불균형 자료(예 : 양품 vs 불량 비율) : 대부분 제조업의 경우 불량 분석을 위해 빅데이터를 활용하는데, 양품의 비율이 불량의 비율보다 월등히 높습니다.(그렇지 않으면 이익이 나지 않겠죠?) 따라서 데이터의 불균형이 매우 심합니다.
3) 현업에서의 데이터 분석 사례 : 통신/마케팅
통신, 마케팅 분야에서는 데이터를 활용하여 아래와 같은 작업을 수행합니다.
1) 상품 추천 2) 영화 추천 3) 상권분석 및 매장분석
사용 알고리즘 : 연관규칙 알고리즘 : 특정 상품을 살때 어떤 상품을 같이 사는지 분석 협업필터링 : 비슷한 사람들을 분류하여 비슷한 마케팅 진행
4) 현업에서의 데이터 분석 사례 : 금융/보험
금융/보험 분야에서는 데이터를 활용하여 아래와 같은 작업을 수행합니다.
1) 고객이동경로분석 2) 신용평가 3) Fraud Detection System 4) 운전 습관을 통한 보험료율 책정/할인 5) 건강 관리를 통한 보험 할인 6) 보험 사기 방지
제약 사항 : 고객정보 공유 규제(유출 시 막대한 피해)
5) 현업에서의 데이터 분석 사례 : 헬스케어
금융/보험 분야에서는 데이터를 활용하여 아래와 같은 작업을 수행합니다.
1) 질병 감시/예측 서비스 2) 의료 빅데이터 및 AI : DNA, 진단정보, 의료차트 등을 활용한 예측 서비스 및 Computer Vision을 활용한 판정 빅데이터와 AI를 활용한 신약 후보물질 제안
#2. 기초 통계
1. 기술통계 : 수집한 자료를 분석하여 대상들의 속성을 파악하는 통계방법
- 평균(mean)
- 중앙값(median)
- 최빈값(mode)
- 분산(variance)
- 공분산(covariance)
- 상관계수(coefficient)
2. 추리통계 : 모집단에서 표본을 추출하고 표본의 기술통계를 통해 모집단의 특성을 추측하는 것
표본의 기술통계를 통해 모집단의 특성을 추측했을 때, 이 추측이 100% 맞진 않습니다. 따라서 우리는 신뢰구간이란 것을 정하여, 모집단의 특성이 표본을 통해 얻은 추측 범위 안에 들어갈 구간과 그 구간 안에 모집단이 들어갈 확률을 구합니다.
- 모집단: 연구 또는 분석의 전체 집단
* 모집단은 실시간으로 변하는 경우도 있어 모집단 전수 조사는 매우 어렵다.
- 신뢰구간 : 추리통계에서 예측한 모집단의 특성이 위치할 가능성이 높은 구간
- 신뢰수준 : 신뢰구간에 모집단의 특성이 위치할 확률
- 표본 : 모집단에서 추출한 일부로, 모집단의 속성들을 유추하는데 사용된다.
1) 확률표본추출방법 : 모집단에서 무작위로 표본을 추출하는 방법
2) 비확률표본추출방법 : 조사자의 편의나 판단에 의해 표본을 추출하는 방법
* 비확률표본추출방법에는 층화추출법 등 다양한 방법이 있습니다. 표본 추출 시에 편향된 표본을 고르는 것이 아닌지 항상 의심해봐야 합니다.
2. 변수의 종류 및 분석법 :
* Variables : 데이터를 구성하는 변수
1) Numerical : 숫자형 데이터
1.1) Continuous : 연속형
1.2) Discrete : 불연속형
2) Categorical : 범주형 데이터
2.1) Regular Categorical : Ordinal이 아닌 경우
2.2) Ordinal : 범주들 사이에 서열/순서가 존재하는 경우
* 척도
1) 비연속형 변수
- 명목척도: 상호배타적인 특성만을 가진 척도 ex) 남/여
- 서열척도: 명목척도 중 항목들 사이에 서열이나 순위가 존재하는 척도 ex) 언론에서 발표하는 대학 순위
2) 연속형 변수
- 등간척도: 서열척도들 중 항목들 간의 간격이 일정한 척도 ex) 섭씨온도 : 섭씨 0도는 열이 없는 상태가 아니기 때문에 섭씨온도는 등간척도이다.
- 비율척도: 등간척도 중 아무것도 없는 상태를 0으로 정할 수 있는 척도 ex) 무게
* 데이터 표현 방법
1) 도수분포표 : 특정 항목 또는 범위에 속하는 빈도수를 나타낸 표
2) 막대그래프 : 비연속형 변수에 사용되는 그래프, 항목별 빈도수를 나타냄
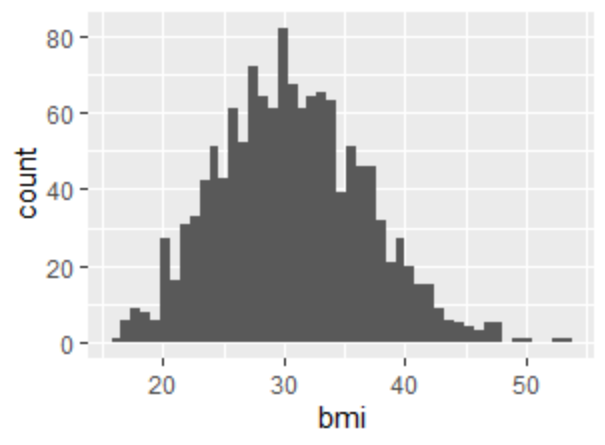
3) 히스토그램 : 연속형 변수에 사용되는 그래프
4) 선그래프 : 히스토그램의 끝 부분을 선으로 연결한 그래프
* 가설과 신뢰수준/유의확률
1)귀무가설(영가설): 연구가설과 반대되는 가설, 실제 분석이 이루어지는 가설
2) 대립가설(연구가설): 분석을 통해서 알아보고자 하는 내용으로 이루어진 가설
- 귀무가설은 하나의 통계값으로 나타낼 수 있어야 하며 귀무가설 과 대립가설은 동시에 참/거짓일 수 없다.
* 유의확률(p-value): 실제로는 귀무가설이 참임에도 통계분석을 통해 귀무가설을 거짓으로 판단할 가능성 : 실제 현상을 반영하지 못할 가능성
5) 다수준분석: 독립변수와 종속변수의 수준이 다른 경우, 독립변수와 종속변수는 개인수준이지만 조절변수의 수준이 다른 경우의 분석(복잡한 사회현상에 대해 분석)
# 머신 러닝 및 딥러닝
머신 러닝이란 컴퓨터가 데이터를 학습하는 알고리즘과 기술의 총칭이며 지도학습, 비지도학습, 강화학습으로 분류된다.
1. 지도학습(Supervised Learning)
: 입력 데이터(X)와 타겟값(Y)를 알고 있는 데이터를 학습하여, 이들의 관계를 모델링하는 방법
지도학습은 타겟변수(Y)의 형태에 따라 두 가지로 나뉠 수 있다.
1) 분류(Classification)
: 타겟변수 Y가 불연속형 변수(Discrete Variable)인 경우, 입력값(X)이 주어질 때 해당 입력값이 해당되는 클래스(Y)를 예측한다.
ex) 스팸 메일 분류, 얼굴 인식
2) 회귀(Regression) : 타겟변수 Y가 연속형 변수(Continuous Variable)인 경우 입력값 x가 주어질 때 해당 입력값과 매칭되는 Y값을 예측한다.
ex) 주가 예측
2. 비지도학습 : 타겟값(Y)이 없는 입력 데이터만이 주어질 때 학습하는 방법(입력 데이터에 내재되어 있는 특성을 찾아내는 용도)
1) 군집화(Clustering) : 유사한 포인트들끼리 그룹을 만드는 방법 2) 잠재 변수 모델(Latent Variable Model) : 표현된 데이터 속에 내재되어 있는 요인을 찾는 것 ex) 주성분 분석, 특이값 분해, 비음수 행렬 분해, 잠재 디리슐레 할당.... 3) 밀도 추정(Density Estimation) : 관측된 데이터를 이용하여 데이터 생성에 대한 확률밀도함수를 추정 4) 이상치 탐지 5) 인공신경망 기반 비지도학습(ex : GAN)
3. 강화학습
: 자신이 한 행동에 대한 "보상"을 바탕으로 목적을 달성하는 학습
4. 딥러닝 : 인공신경망을 활용하여 컴퓨터를 학습시키는 기법
* Perceptron : 생물학적 뉴런을 모방하여 만든 인공신경망의 기본 단위
< 실제 뉴런과 Perceptron의 비교 모습 >
위와 같이 a,b라는 input을 받아서 합친 뒤 activation function을 통과하여 최종 출력을 내보내는 것을 볼 수 있습니다.(이 결과는 다음 Perceptron(혹은 뉴런)으로 전달되거나, 최종 Output으로 출력됩니다.)
* DNN(Deep Neural Network) : 아래 그림과 같이, Neural Network는Input Layer,Hidden Layer,Output Layer로 구성됩니다. Input Layer와 Output Layer는 하나지만, Hidden Layer는 여러개일 수 있고, Hidden Layer가 2개 이상일 때Deep Neural Network이라고 합니다. Hidden Layer가 늘어날수록, 더 정교한 모델을 만들 수 있지만, 계산량의 증가와Overfitting을 항상 주의해야 합니다.
* 각각의 Node들을 하나의 Perceptron이라고 생각하시면 됩니다.
* 용어 :
1) Weight(가중치)
위의 그림의 Hidden Layer의 각 Node(동그라미)들은 모두 가중치라는 값을 가지고 있습니다. 이 값들은 각 Node들의 결과값에 곱해진 후 다음 노드로 전달됩니다. Neural Network는 데이터를 사용하여 이 가중치들을 최적의 값으로 Update하는 것이 목표입니다.
2) Loss Function(Cost Function) : Input Layer, Hidden Layer를 거쳐 최종적으로 Output Layer에 도착한 결과값은, Loss Function이란 함수에 넣어져 실제 값과의 차이를 계산하게 됩니다. 이 결과값이 오차이고, 이 오차를 줄이기 위하여 Loss Function을 미분하여 Loss Function을 감소시키는 방향으로 가중치를 Update하는 것이 Gradient Descent 입니다.
3) back propagation : 역전파 Neural Network는 주어진 데이터를 활용하여 가중치를 Update함으로써 최적의 모델을 만듭니다. Output Layer에서 구해진 오차를 활용하여 가중치들을 Update해야 하는데, Update하는 방법이 역전파입니다. 역전파는 아래의 그림과 같이 각 단계별로 관계식을 구한 후 미분한 뒤, 이 미분값들을 모두 곱하여 Loss Function을 가중치로 편미분한 값을 구할 수 있습니다.
4) overfitting(과적합) : 모델을 학습시킬 때 일반적으로 데이터셋을 train, validation, test라는 세가지 데이터셋으로 나눕니다. Training set으로 학습시킬 때의 Error를 training error, Test Set의 데이터를 입력했을 때의 오차를 test error라고 하는데, 이 두가지 변수는 항상 동일한 것은 아닙니다. (이상적으로는 Training Error와 Test Error가 동일해야 합니다.) Training Set을 활용하여 학습하는 동안 training error가 너무 낮아지면, 모델이 새로운 데이터(Test Set)에 대해 반응을 못하여 test error가 높아질 수 있습니다. 이런 경우를 overfitting이라고 합니다. 이와 반대로 아예 학습이 잘 되지 않아 Training Error가 높은 경우를 underfitting 이라고 합니다.
* 딥러닝의 활용
1) CNN convolutional network는 컴퓨터비전에 활용되는 Deep Neural Network입니다.
2) Recurrent Neural Network * Sequence is important ! : 사람의 말을 해석할 때, 아래 글과 같이 앞뒤의 문맥을 이해하고 있는 것이 중요합니다. 아래 사진의 두 문장을 보았을 때 뒤의 문장은 동일하게 '이 영화 꼭 보세요!' 지만, 앞의 내용에 따라 완전히 다르게 해석될 수 있는 것을 알 수 있습니다. 이처럼 자연어 처리에서 언어를 해석할 때, 문맥이란 개념을 도입하기 위해 사용하는 Neural Network이 RNN입니다.
RNN은 아래 그림과 같이 Network들이 Sequence를 가지고 연결되어 있습니다. 이런 방식으로 앞의 해석 결과가 뒤의 해석 결과에도 영향을 미칠 수 있는 것입니다.
하지만 RNN은 아래와 같은 문제들을 가지고 있고, 이 문제들을 해결하기 위한 방법들도 어느정도 제시되어 있습니다.
문제 ) 1. Sequence가 길어지면 성능이 떨어진다. 2. Sequence가 길어지면 학습이 잘 안된다. 3. 오래전 입력에 대해서는 기억을 잘 못한다.
비지도학습의 한 종류로, 서로 대립하는 두 신경망(모델)을 경쟁시켜서 좋은 성능을 얻어내는 Deep Learning Algorithm 입니다. 아래 그림과 같이 하나의 생성 모델, 하나의 분류 모델이 있다고 가정해봅시다. 생성모델에서는 가짜 지폐 데이터를 생성하고, 분류모델에서는 이 데이터를 진짜/가짜로 분류합니다. 이 과정을 계속 반복하면서, 점점 더 정교하게 성능을 향상시키는 것입니다.
##5 lm( )과 rpart( )를 활용하여 ## 관심변수 charges를 나머지 변수로 설명하는 모형 적합하기
?lm
lm(insurance$charges ~ insurance$age)
ggplot(insurance, aes(x = age, y = charges)) + geom_jitter()
linear_model = lm(charges ~ age + bmi + sex + children + smoker + region , data = insurance) summary(linear_model) rpart_model = rpart(charges ~ age + bmi + sex + children + smoker + region , data = insurance) summary(rpart_model)
총 113강을 10주동안 공부했으니 일주일에 약 11개의 강의씩을 들은 셈입니다. 수강한 강의들에 대해서 평가하자면, 전반적으로 입문자를 대상으로 하고 있습니다. 요즘 데이터 사이언스가 핫하다고 하는데 뭐하는 직무 또는 학문일까? 라는 질문을 가지신 분이 가볍게 들어보시기에 좋은 것 같습니다. 실제로 113강도 하나의 강의당 평균 10분정도 남짓이라 수강 시간도 매우 짧았습니다.
좋은 점은 누구나 부담없이 들을 수 있는 수준의 강의라 좋았습니다. 단점은 강의가 모두 한명의 강사가 진행하는 것이 아니라서 강의내용이 일부분 겹치는 부분들이 있고, 전반적인 내용의 흐름이 아주 매끄럽진 않았습니다.
하지만 이후의 패스트캠퍼스의 강의들을 추가로 들을 예정인 저로써는 시작하기에 아주 좋은 강의였던 것 같습니다. 이상 끝-!
##5 lm( )과 rpart( )를 활용하여 ## 관심변수 charges를 나머지 변수로 설명하는 모형 적합하기
lm(insurance$charges ~ insurance$age)
ggplot(insurance, aes(x = age, y = charges)) + geom_jitter()
위의 그래프는 [나이 - 보험청구료] 산점도입니다. 관찰해보면 명확히 3개의 그룹으로 나눠져있는 것을 볼 수 있습니다.
linear_model = lm(charges ~ age + bmi + sex + children + smoker + region , data = insurance) summary(linear_model) rpart_model = rpart(charges ~ age + bmi + sex + children + smoker + region , data = insurance) summary(rpart_model)
* 사건 : 관측치나 데이터가 특정 조건을 만족시키는 상황 * 확률 : 관심 있는 사건이 발생할 가능성을 0과 1 사이의 값으로 표현한 값
* 확률을 계산하는 다양한 방법 1) 경우의 수 2) 모의 실험 3) 데이터 활용
데이터 공간의 구성 : 변수만큼 차원이 생성, 관측치 수만큼 해당 차원에 점이 생성
* 분포 : 관측치들이 공간에 퍼져있는 모양 * 밀도 : 어떤 분포에서 특정 값이나 구간의 관측치 비중을 표현한 숫자. 전체 밀도(면적)의 합은 1이 되어야 한다.
* 조건부 확률 : 특정 조건을 만족하는 관측치의 확률
* 독립 : 두 사건 A, B가 서로 관계가 없는 경우
전체에서의 A의 비율과, B 내에서의 A의 비율이 같다면, A와 B는 독립임을 벤다이어그램으로 위와 같이 나타내볼 수 있습니다. 이 말은 즉, A는 매우 골고루 분포되어 있고 B라는 사건의 발생 여부에 영향을 받지 않는다는 것을 의미합니다.
6. 모집단과 표본의 개념 이해하기
1) 모집단 : 관심있는 대상 전체
2) 표본 : 모집단에서 추출한 관심 대상 일부
3) 추정(estimation) : 데이터로 모집단의 특성을 확인하는 과정
4) 검정(test) : 확인된 차이의 유의미 여부나 가설의 타당성을 판단하는 과정
7. 통계 검정의 개념 이해하기
검정의 활용 : 데이터 속 차이나 변수 간의 관계 등이 유의미함을 보일 때 활용 - 귀무가설과 대립가설 중 확률적으로 더 높은 쪽을 선택하는 과정 - 보수적으로 판단하기 위해서 귀무가설을 기준으로 판단한다.
귀무가설 : 차이, 관계가 없을 가정 대립가설 : 귀무가설과 반대로 차이, 관계가 있음을 가정
* 유의확률(p-value) : 귀무가설이 맞다는 가정 하에 데이터 속 차이나 관계가 나올 가능성을 계산한 조건부 확률 유의확률 < 0.05 : 대립가설을 선택 유의확률 > 0.05 : 귀무가설을 선택
=> p-value : 귀무가설이 맞다고 가정할 때 현재의 특성이 나올 확률
*유의수준 (significant level) : 유의확률에 대한 판단의 기준값
ex) 관측 결과를 통한 모집단 유추 검증 예시 :
빨간 공과 파란 공으로 이루어져 있는 모집단에서 10개의 공을 뽑았더니 7개의 빨간색 공과 3개의 파란색 공이 나왔다. 모집단의 비율을 유추해보자.
귀무가설 : 모집단의 빨간공 / 파란공 비율은 0.5이다.( = 1:1이다)
대립가설 : 모집단의 빨간공 / 파란공 비율은 0.5가 아니다.
위와 같이 관측치가 나왔을 때, 귀무가설이 유의미한 결론인지, 대립가설이 유의미한 결론인지 파악해야 합니다. 따라서 귀무가설이 참이라는 가정 하에(빨간공의 개수 = 파란공의 개수) , 이항분포를 그려봅니다. 위의 사진 아래쪽의 표는, 빨간 공과 파란 공의 개수가 같을 때, 10개의 관측치 중 x개의 빨간 공이 관측될 확률입니다.
모집단의 빨간 공과 파란 공의 개수가 같을 때, 모집단에서 10개의 공을 뽑아 7개 이상의 빨간 공이 관측될 확률은 표의 빨간색 부분의 확률을 합친 결과와 같다( = 0.172). 유의 수준이 0.05라고 할 때, 0.172>0.05이므로 우리는 귀무가설을 택한다.
이 결과를 해석해보면, 귀무가설을 가정했을 때, 현재 발생한 사건이 극적으로 낮은 확률에 의해 나타난 관측치는 아닌가?를 검정해보는 과정이다. 실험 결과 유의수준(p-value)가 0.172로 그렇게 낮은 확률이 아님을 확인했고, 따라서 우리는 귀무가설을 택한다.
ex) 상관계수의 의미 검증 : 공부시간과 성적의 상관계수가 0.7이 나왔다. 의미있는 것인가?
귀무가설 : 공부시간과 성적은 상관이 없다.(상관계수 = 0)
대립가설 : 두 변수가 상관이 있다.(상관계수는 0이 아니다.)
- 랜덤으로 공부시간 - 성적을 매칭하고 상관계수를 구한다(1000개) - 상관계수의 분포표를 그리고 0.7이 나올 확률(p-value)를 구한다. - 유의확률을 구한다.(0.025) < 0.05이므로 대립가설인 성적과 공부시간은 관계가 있다 를 선택한다.
9. 검정 통계량의 활용
검정 통계량 : - 데이터 속에 있는 차이, 관계의 정도를 숫자로 표현 - 데이터가 귀무가설과 얼마나 다른지 계산한 통계량 - 보통 검정 통계량이 클 수록 차이가 크다.
1. 상관분석 : 두 수치형 변수의 상관계수에 대한 유의성 검정 - 이전 예제에서는 우리가 직접 랜덤하게 데이터를 만들었지만, 이미 통계학자들이 만들어놓은 T 분포와 T값을 통해 확인해볼 수 있음.
2. 교차표의 독립성 검정 : 카이제곱값(실제값과 예상값의 차이의 크기)을 활용
- 두 범주형 변수가 서로 독립인지 아닌지를 판단하는 과정(독립 = 두 변수는 관계가 없다)
* 귀무가설 : 두 변수는 독립이다.(관계가 없다.)
* 대립가설 : 두 변수는 독립이 아니다.(관계가 있다.) - 두 범주형 변수의 교차표와 독립을 가정한 교차표를 비교 1) 아래와 같이 기본적으로 주어진 표(파란색)을 가지고, 독립일 경우의 표(빨간색)과 비교한다. 빨간색 표는 합계들을 기반으로 채워볼 수 있다. (ex : 20대-A는 연령별 비율 0.3, 상품별 비율 0.5이므로 독립임을 가정하면 100 * 0.3 * 0.5 = 15이다.) 이와 같이 두 교차표를 뺀 뒤 각각 제곱을 한 뒤 더하면, 우리가 원하는 카이제곱값을 얻을 수 있다. 이 카이제곱값을 자유도 분포에 넣어주면 유의수준을 구할 수 있다!
3. 그룹별 평균 차이에 대한 검정
분산분석(ANOVA) : - 그룹별 평균의 차이가 유의미한지를 검정 - 전체 그룹 평균 대비 그룹별 평균 차이의 정도를 측정
?자유도는 도대체 어떤 의미를 가지는가?
12. 데이터를 활용한 예측
기술통계와 추론통계
*확률 모형 : 과거, 현재를 바탕으로 미래 예측
* 심슨의 역설 : 어떤 집단이 모든 부분에서 상대적으로 확률/평균이 높아도 전체 확률/평균은 오히려 작은 현상 - 그룹별 확률/평균 차이와 집단별 선호 그룹의 차이로 발생
13. 확률모형의 이해
* 지도학습(supervised learning) : 관심변수와 설명변수의 관계를 확인하여 예측에 활용
* 범주형 관심변수 : - 관심 사건을 정의하거나 실제 범주형 변수에서 관심있는 수준을 선택
ex) 카드사용금액대에서 100만원 이상
- 설명변수를 활용한 조건부 확률을 계산 ex) 연령, 거주지 등 신상정보와 금융정보를 활용하여 카드 사용금액이 100만원 이상일 확률 예측
* 다중 선형 회귀 모형에서는 선형대수학을 공부해야 한다. 행렬간의 곱은 공분산을 계산한 것.
* 변수 선택 : 확률 모형에서 필요한 설명 변수만 선택하는 과정
15. 나이브 베이즈 판별기 : 복수의 설명변수 조건에 따라 관심변수의 수준을 예측 - 설명 변수 간 독립을 가정하고 각 조건부 확률을 곱해서 예측
* 베이즈 정리 :
* 나이브 베이즈 판별기 직접 한번 써보기 장점 : 확률 계산의 편의성 단점 : 설명 변수 간의 조건부 독립을 가정
16. 의사결정 나무모형
* 분할 : : 설명 변수에 조건을 추가하여 관측치를 분할한다. - 조건부 평균이나 조건부 확률의 차이를 기준으로 분할 기준을 설정한다.
* 재귀 분할 : 상위 그룹을 분할하고 분할된 그룹을 또다시 분할하는 과정을 반복
* 가지치기 : 분할된 그룹 중 그룹 간 차이가 충분히 크지 않은 그룹을 제거한다.
* 의사결정나무 : 설명변수를 활용하여 관측치 그룹 간 관심 변수의 차이를 설명
- 수치형 관심변수 : 조건부 평균의 차이를 계산 - 범주형 관심변수 : 조건부 확률의 차이를 계산
* R 실습
* choose(전체 개수, sample 개수) : 조합의 수 계산 * mean(SCORES$국어점수>=90) 와 같이 Boolean 상태에서 평균을 구하면 해당 조건을 만족하는 비율을 구할 수 있다. * hist(x, probability = True) => 밀도로 변환 가능 * subset(데이터, 조건) * sample(1:45, 6, replace = 복원추출 가능 여부, defalut False) : 45개 숫자 중에서 6개를 임의로 샘플링한다. * cor.test(heights$father, heights$son) 두 변수의 상관계수를 구하고, 그 유의미성 또한 검증할 수 있다. * chisq.test(table_raw) 교차표에서의 변수간의 독립성을 검증할 수 있다. * aov(SCORE ~ TEAM, data=team_score) : 분산분석 * lm(종속변수 ~ 독립변수) * rpart : 의사결정나무모형 만들기
은행/카드사 - 거래 내역, 보유 재산, 신용 정보 등의 데이터를 보유하고 있습니다. 은행 및 카드사는 데이터를 반드시 축적해야 계좌 및 금액 관리가 가능합니다. 통신사 - 유동인구 데이터, 전화량, 데이터 사용량 등 무궁무진한 데이터를 보유하고 있다. 카드사와 통신사는 일반적으로 제휴를 많이 맺고 있습니다. 여론조사 기관 - 정교한 샘플링으로 데이터를 수집합니다. 제조업 - 공정데이터를 가지고 있습니다. 제약 - 신약 후보 물질 탐구, 신약의 효과 검증을 위해 데이터 분석을 활용합니다. 공공기관 - 교통정보, 기상정보, 건강보험정보, 소득정보 등의 데이터를 보유하고 있습니다.
데이터 분석은 데이터를 요리해서 우리에게 필요한 해결방안을 도출해내는 것입니다. 데이터는 객관적이지만 사람의 판단은 주관적이기 때문에, 같은 데이터로 분석을 해도 결과는 매우 달라질 수 있습니다.
2. 차이에 대한 개념 이해하기
1) 데이터 구성 : 데이터는 변수와 관측치로 구성되어 있습니다.
1. 범주형 변수(Categorical Variable )
: * 관측치간 차이를 나타내는 방법
1. 절대적인 차이(95점) 2. 상대적인 차이(30명 중 3등)
* 범주형 변수의 요약 방법 1) 빈도표 : 수준간 절대적인 차이 2) 상대빈도 : 수준간 상대적인 차이 3) 막대 그래프 ( 절대적인 차이 ) 4) 원 그래프 ( 상대적인 차이 ) 2) heat map : 숫자 대신 색의 진하기로 크기를 표현
2. 수치형 변수(Numeric Variable)
* 수치형 변수의 요약 방법
1) Box Plot : 사분위수를 활용하여 나타낸 그래프 2) 도수분포표(contingency table) 3) 히스토그램 : 구간별 관측치를 나타낸 그래프 4) 기술통계 : - 평균/중앙값 - 분산/표준편차 5) 산점도 : 두 수치형 변수를 가로축, 세로축으로 활용하여 그린 그래프 각 변수별로 평균선을 그리면 양/음의 상관관계를 쉽게 나타낼 수 있다.
* 수치형 변수의 상대적인 값으로의 변환
1) 백분율 2) 최소-최대 정규화 3) 표준화 (Z값) : 평균으로부터 떨어진 정도를 표준편차의 단위로 표현
* 공분산 : 두 변수의 상관관계를 나타내는 방법 중 하나
* 공분산의 문제점 : 공분산은 scale이 크고, unit이 복잡합니다. 이러한 문제점을 해결하기 위하여 상관계수가 등장합니다. → 상관계수는 1과 -1 사이의 값만 가집니다.
4. 범주형 변수와 수치형 변수의 관계
1) 조건부 평균 : 범주형 변수의 수준별로 관측치를 나누고, 그룹마다 평균을 비교한다. 2) 수치형 변수의 구간화 : 수치형 변수를 구간화함으로써 범주형 변수 2개 사이의 관계를 알아본다.
5. 선형회귀
: 주어진 두 수치형 변수 사이의 관계를 일차함수로 나타내는 방법
* 관심변수(반응변수, 종속변수) * 설명변수(독립변수)
추세선 : 독립변수와 종속변수의 관계를 직선으로 나타낸 것. 두 수치형 변수의 관계를 파악할 수 있다.
선형회귀 : 주어진 데이터를 활용하여 두 변수의 관계를 가장 잘 나타내는 B0, B1 변수를 구하는 방법.
* 선형회귀에 사용되는 방법 :
최소제곱법(least squares approximation)
회귀직선의 기울기는 두 변수의 상관계수에 비례한다.
예측 값(B0)을 살펴보면 예측된 Y값이 평균 중심으로 당겨지는 것을 확인할 수 있다.
6. 예측
1) 범주형 변수를 활용한 예측 전략 범주형 범주인 설명변수 - 구간별 평균을 통해 예측 가능
2) 수치형 변수를 활용한 예측 전략 수치형 변수의 구간화 : 산점도와 상관계수를 활용한다