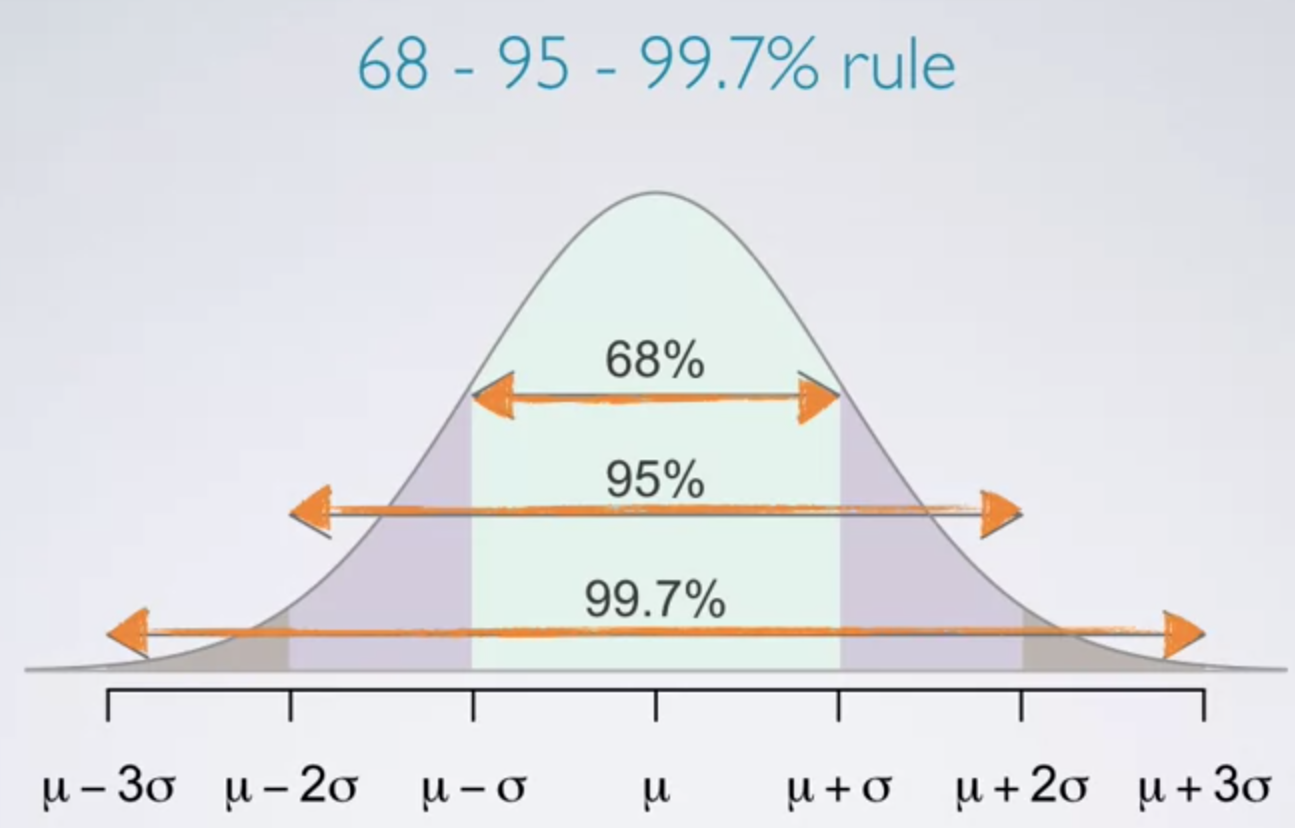
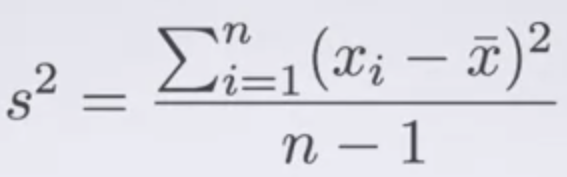정규분포를 그리는 그래프에서는 아래 그림과 같이 평균을 기준으로 (1 * σ) 범위 내에는 68%의 데이터가 존재하고,
(2 * σ) 범위 내에는 95%의 데이터가, (3 * σ 범위) 내에는 99.7%의 데이터가 존재합니다.
2. Standardizing with Z scores
Z score란 관측치에서 평균을 뺀 뒤 표준편차로 나눈 것으로, 관측치가 평균에서 얼마나 떨어져있는지 표준편차를 사용하여 확인하는 방법입니다. |Z| > 2 * σ라면 이상 관측치로 분류할 수 있습니다.
Z = (observation - mean) / standard deviation
3. percentile : percentage of observations that falls below a given data point
4. Normal Probability Plot
Normal Probability Plot은 오른쪽 그래프와 같이 데이터의 분포가 정규분포를 얼마나 따르는지 확인할 수 있는 그래프입니다. 데이터의 분포가 정규분포를 만족할수록 그래프는 직선에 가깝게 됩니다. x축은 theoretical quantile, y축은 관측치입니다.
위의 그림과 같이, Normal Probability Plot을 통해 그래프의 분포도를 유추해볼 수 있습니다.
5. Binomial Distribution
: the binomial distribution describes the probability of having exactly k successes in n independent Bernouilli trials with probability of success p
- Mean and Standard Deviation of binomial distribution :
-Bernoulli random variable : when an individual trial has only two possible outcomes.
6. Normal approximation to binomial
: as samples size increases, the binomial distribution looks much similar to the normal distribution.
이 특성을 사용하여, 큰 sample size의 binomial distribution에 대해 normal distribution에 사용하는 방법과 마찬가지로 percentile을 구할 수 있다. 이 sample size의 크기는 아래와 같은 조건을 만족할 때 Normal Distribution과 같은 방법을 사용할 수 있다.
* 이 때 0.5정도의 관측치 조정을 통하여 정확한 값을 구할 수 있다.(70이상의 값은 70을 정확히 포함하지 않으므로 0.5를 빼서 Z score를 구한다.)
- Binomial Conditions :
1) The trials must be independent
2) the number of trials, n, must be fixed
3) each trial outcome must be classified as a success or a failure
4) the probability of success, p, must be the same for each trial
Introduction to Probability and Data 강의에서는 보조교재 OpenIntro Statistics 의 병행 학습을 권장하고 있습니다.
Week 1의 권장 학습 목록
Suggested reading:Chapter 1, Sections 1.1 - 1.5
Practice exercises:End of chapter exercises in Chapter 1: 1.1, 1.3, 1.11, 1.13, 1.17, 1.19, 1.25, 1.27, 1.31
1.1 ) Case study: using stents to prevent strokes
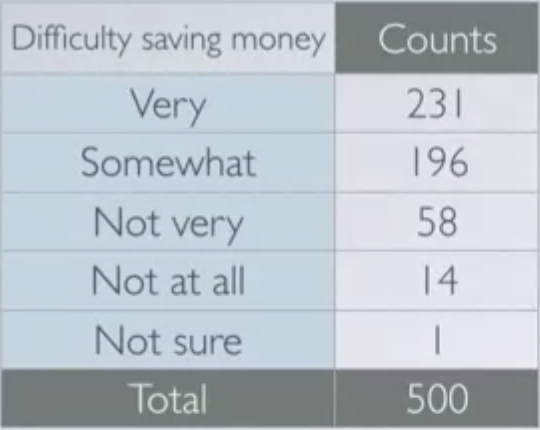
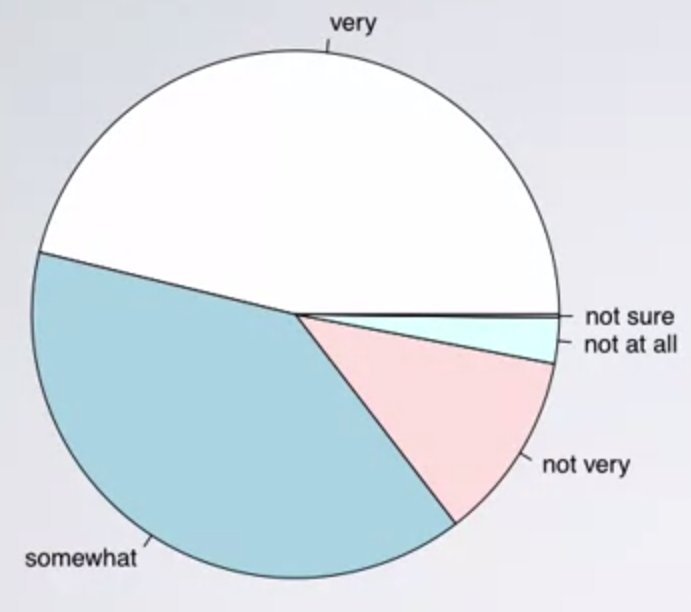
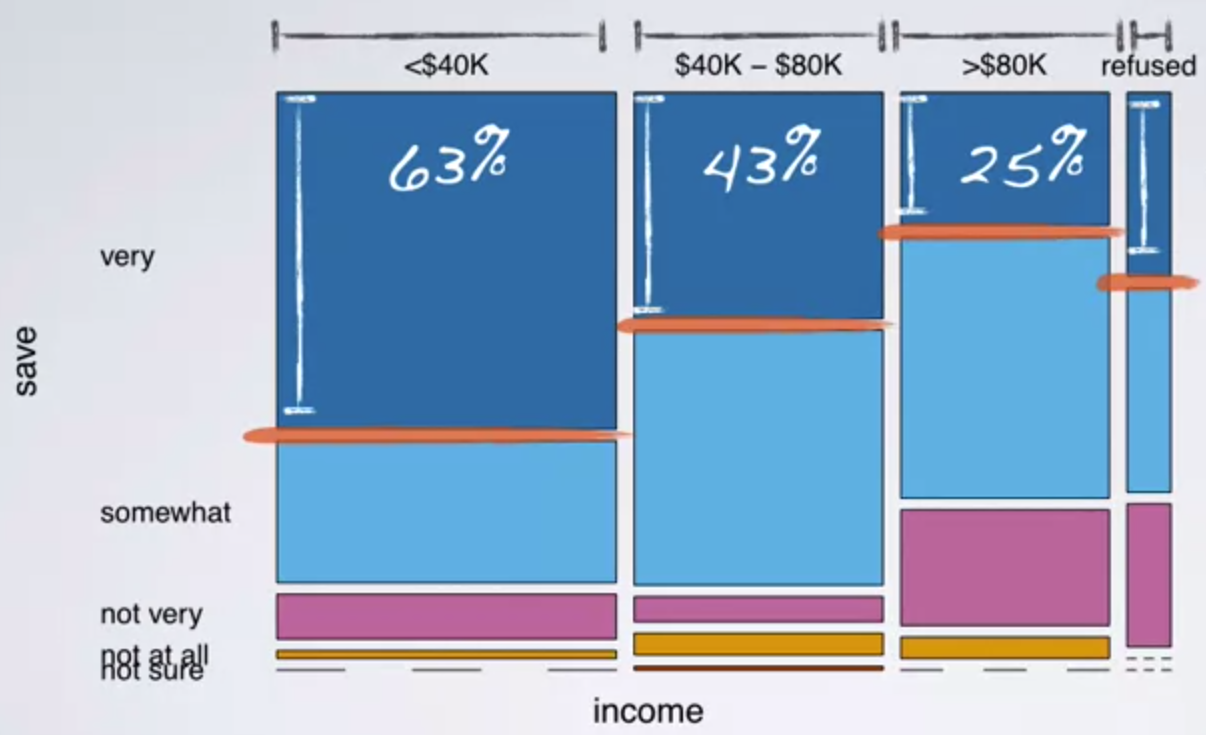
Stent란 혈관 폐색을 막기 위해 혈관에 주입하는 의학 기구입니다. 이번 장에서는 stent가 심장마비에 효과가 있는지 살펴봅니다. 연구자들은 451명의 심장마비 위험군 환자들을 대상으로 진행되었고, 통제집단과 실험집단은 다음과 같이 구성되었습니다.
실험집단 : Stent 삽입 및 건강관리 (224명의 환자)
통제집단 : 건강관리 (224명의 환자)
간단한 실험의 결과는 아래와 같습니다.
=> 실험 집단 중 1년 안에 심장마비가 온 사람들의 비율을 구하는 문제입니다. 답은 45/224 = 20%입니다.
추가적으로 통제집단의 1년 내 심장마비 발생률은 28/227 = 12%입니다.
연구자들이 기대한 내용과 반대의 결과가 관찰되었습니다. 이 데이터를 통해 우리는 이 결과에 대해 다음과 같은 결론을 내릴 수 있습니다. '회사 내 환자 집단에 대해서 stent는 심장마비에 안좋은 영향이 있다.' 는 것입니다.
여기서 조심해야 할 것은 두가지 입니다.
1. 해당 시험은 연구에 자원한 환자들에 대하여 실험된 것이므로, 전체 심장마비 환자에 대해 대표성을 띈다고 보기 어렵습니다. (그런데 모든 환자에 대한 대표성을 띄는 표본으로 연구를 하는 것이 가능한가..?라는 생각이 듭니다. 인간을 대상으로 하는 연구는 Random Sampling + Random Assignment가 매우 어렵다고 하는 것이 이해가 됩니다.
2. 코인을 100번 던진다고 해봅시다. 뒷면이 나올 확률은 50%지만 실제로 50번의 뒷면이 관찰되지는 않습니다. 더 많은 시도를 할수록 50%에 수렴할 확률은 높아지지만, 확률적으로 분산만큼 다른 분포를 보일 수도 있습니다.
1.2) Data Basics
1.2.1) Observations, variables, and data matrices
별 내용이 없습니다..
1.2.2) Type of Variables
1) Numerical
1.1) Continuous
1.2) Discrete
2) Categorical
1.2) Ordinal
1.2) Nominal
1.2.3) Relationships between variables
1) Dependent :
1.1) Positive Association : 양의 상관관계
1.2) Negative Association : 음의 상관관계
2) Independent : 변수 사이에 상관관계가 없는 경우
* Dependent variable(associated variable, 종속변수) : 서로 관계가 있는 변수
1.3) Overview of Data collection principles
1.3.1) Populations and samples
조사를 할 때는 목표 모집단이 무엇인지, 표본 추출 방식이 무엇인지 항상 유의해야 합니다.
표본(sample) : a subset of cases which represents the entire population
1.3.2) Anecdotal evidence(입증되지 않은 증거)
표본에 대한 결과를 살펴볼 때, 표본이 모집단을 대표하는지 항상 확인해야 합니다. 계획적으로 샘플링되지 않은 데이터를 Anecdotal Evidence라고 합니다.
1.3.3) Sampling from a population
Sampling은 bias(편향) 없이 random하게 이루어져야 합니다. 이런 Bias(편향)은 여러 경우로 나타납니다.
1) 무응답(Non-Response)
설문조사를 Random하게 진행했을 때 응답률이 30%에 불과하다면, 결과가 일반화가 가능한지는 의심해봐야 합니다. 무응답 비율이 높은 조사의 경우, 표본집단이 대표성을 띄지 않을 수도 있습니다.
2) Convinience Sample
설문조사를 진행하면, 접근하기 쉬운 사람들이 조사 대상에 많이 포함될 수 있습니다. 이런 경우에도 표본집단이 모집단을 대표하는지 의심해볼 필요가 있습니다.
1.3.4) Explanatory and response variables
1) explanatory variable(설명 변수) :
2) response variable(응답 변수) :
* Association does not imply causation : 두 변수간의 상관관계가 보이더라도, 이것이 두 변수간의 인과관계를 의미하진 않는다. 또한 어떤 것이 설명변수이고, 어떤 것이 응답변수인지 방향성이 확실하지 않은 경우도 있습니다.
1.3.5) Introducing observational studies and experiments
1) observational study : data의 발생과 상관없이 data를 수집하여 분석하는 경우. 변수들간의 상관관계는 파악할 수 있지만, 인과관계를 파악하긴 힘듭니다.
1.1) Prospective Study
1.2) Retrospective Study
2) experiment : 변수들간의 인과관계를 파악하는 실험방법. data 수집 시 표본집단을 구분하여 변인들을 분배합니다.
1.4) Observational studies and sampling strategies
Observational Study는 변수들 간의 상관관계를, Experiment에서는 인과관계를 도출해낼 수 있습니다.아래의 예시에서 볼 수 있듯이, Observational Study로부터 변수들 간의 인과관계를 도출하는 것은 위험합니다.
Ex) 우리는 일반적으로 선크림을 많이 바르면 피부암에 걸릴 확률이 줄어든다고 알고 있지만, Observation Study를 통해 관찰된 결과를 보면, 선크림을 많이 바르면 피부암에 걸릴 확률이 높다고 한다. 무언가 이상하다. 빠트린 것이 무엇일까?
=> 이 관찰 결과에서는 '하루 햇빛에 노출되는 시간' 변수가 빠져있습니다. 하루동안 햇빛에 오래 노출되는 사람들은, 선크림을 바르는 양이 당연히 많을 것이고, 많이 바름에도 불구하고 더 오랜 시간 노출됨에 따라 피부암에 걸릴 확률이 높은 것입니다. 이와 같이 단순히 두 변수 간의 상관관계를 보고 인과관계를 도출하는 것은 매우 위험함을 알 수 있습니다.
이 때 설명변수인 '선크림 사용량'과 응답변수인 '피부암 발병률' 두 변수에 모두 영향을 미치는 '하루 햇빛에 노출되는 시간'변수를 Confounding Variable이라고 합니다.
1.4.2) Four Sampling methods
만일 observational data가 모집단으로부터 random한 방법으로 추출되지 않으면, 신뢰성이 떨어질 수 있습니다. 그럼 이제 Sampling하는 4가지 방법에 대해 알아봅니다.
1) Simple Random Sampling : Random Sampling의 가장 직관적인 방법입니다. 제비뽑기를 뽑듯이 모집단에서 Random하게 Data를 추출합니다.
2) Strafied sampling : Divide-and-Conquer 방식의 Sampling 방법입니다. 모집단이 특성에 따라 여러개의 층으로 나누는 경우, 각 층에 대해서 Random sampling을 진행합니다. 이 방법은 각 층의 Data들이 우리가 관심있는 특성에 대해서 매우 유사한 분포를 보이는 경우에 효과가 좋습니다. 다만 이 데이터들을 분석하는 것이 일반 Simple Random Sampling 보다 좀 더 복잡할 수 있습니다.
3) Cluster Sampling : 모집단을 여러개의 군집으로 나눈 뒤 특정 군집들의 Data들만 Sampling하는 방법입니다.
4) Multistage Sampling : Cluster Sampling에서는 특정 Cluster들의 Data들을 모두 보전했다면, Multistage Sampling 에서는 특정 Cluster들에서 Random Sampling을 진행합니다.
1.5) Experiments :
Studies where the researchers assign treatments to cases. Treatment Assignment가 Randomization을 포함하면, Randomized Experiment라고 부릅니다. Randomized Experiment는 아래와 같은 4가지 법칙을 따릅니다.
1.5.1) Principles of experimental design
1) Controlling : 실험 대상에게 Assign하는 Treatment 외에는 다른 변수들을 통제해야 합니다.
2) Randomization : 통제되지 않는 변수들에 대해서는 실험 대상들을 Random하게 분배합니다.
3) Replication : 최대한 많은 수의 표본을 뽑습니다.
4) Blocking : 때론 treatment 외에 결과에 영향을 미치는 변수를 알고 있을 때에는, 이 변수들에 따라 그룹을 나눈 뒤 각 그룹에서 Random하게 Treatment 그룹에 할당합니다.
1.5.2) Reducing bias in human experiments
Randomized Experiment는 Data Collection에 있어서 최상의 방법이지만, 완벽하게 Bias를 배제할 수 있다는 것을 의미하지는 않습니다. 한 제약회사에서 심장마비에 효능이 있는 신약을 개발하여 실험을 진행한다고 합시다. 실험 기획자는 Volunteer들을 2개의 그룹(Treatment Group/Control Group)으로 나눈 뒤, Treatment Group에만 신약을 투여할 것입니다. 이 때 피실험자의 입장에서 생각해보면, 신약 투여 여부는 환자의 심리적인 상태에 영향을 미칠 수 있습니다. 이것만으로도 실험에 원치 않는 영향을 미칠 수 있는 것이죠.
이런 문제를 피하기 위해서, Blind Experiment를 진행하곤 합니다. 신약이 투여되지 않는 피실험자들은 자신이 어떤 그룹에 속해있는 지 모르도록 가짜 약을 투여받습니다. 이를 Fake Treatment 라고 부르고, 이로 인한 효과를 Placebo라고 부릅니다. 그리고 투약 여부를 몰라야 하는 건(Blind의 대상)은 피실험자뿐만이 아닙니다. 신약 투여 여부에 따라 환자에게 더 관심을 갖거나, 더 주의깊은 치료를 할지도 모르기 때문에 의사/실험 기획자들도 Blind의 대상이 되기도 합니다. 따라서 실험 기획자/피실험자 모두 Blind의 대상이 되는 실험을 진행하게 되고, 이 방법을 Double-Blind라고 합니다.
책을 읽으면서 영어공부도 할 겸, 긴 공부가 될 것 같습니다.(1주일에 4시간 기준 7개월이네요..)
1. Data Basics
Variables : 데이터를 구성하는 변수
1) Numerical : 숫자형 데이터
1.1) Continuous : 연속형
1.2) Discrete : 불연속형
2) Categorical : 범주형 데이터
2.1) Regular Categorical : Ordinal이 아닌 경우
2.2) Ordinal : 범주들 사이에 서열/순서가 존재하는 경우
2. Observational studies & Experiments
Studies
1. Observational : collect data in a way that does not directly interfere with how the data arise("observe")
1.1) retrospective : uses past data
1.2) prospective : data are collected throughout the study
2. Experiment : randomly assign subjects to treatments
Obsevational vs Experiment :
[꾸준히 공부를 하는 것]과 [성적]간의 관계를 파악하는 실험을 계획한다고 합시다.
1) Observational : [꾸준히 공부를 하는 그룹] 과 [꾸준히 공부를 하지 않는 그룹] 을 선별하여 관찰한 뒤, 성적과의 관계를 관찰합니다. 이 결과는 다른 변수들을 고려하지 않기 때문에 [꾸준히 공부를 하는 것] 과 [성적] 간의 직접적인 관계를 설명하는데 적절하지 않을 수 있습니다.
2) Experiment : Random Sampling을 통해 적절한 크기의 표본을 선출합니다.(ex: 100명의 Random한 사람, 인구/연령/성별 고려 x) 이 표본을 [꾸준히 공부하는 그룹]과 [꾸준히 공부를 하지 않는 그룹] 두 영역으로 나눈 뒤, [성적]과의 관계를 관찰합니다. 이 경우에는 다른 변수들을 적절히 섞어주었기 때문에, [꾸준히 공부를 하는 것]과 [성적]관의 관계를 파악해볼 수 있습니다.
=> Observational Study는 상관관계만을 파악할 수 있는 반면, Experiment는 인과관계를 파악할 수 있습니다.
3. Sampling & Sources of bias
1. 전수조사(census) :
전수조사가 좋지 않은 이유:
1.1) 전수조사에 걸리지 않는 사람들이 있을 수 있습니다.(Illegal Immegrants)
1.2) 인구는 언제나 변하므로 완벽한 전수조사란 있을 수 없습니다.
2) 표본조사(sampling) : representitive sample
2. a few sources of sampling bias(편향) :
1) Convenience sample : 쉽게 접근이 가능하여 특정 집단이 표본에 포함될 가능성이 높은 경우
ex) 동네 사람들
2) Non - response : 모수의 특정 집단만이 표본에 포함되는 경우
ex) 가난한 사람들은 설문에 접근, 응답할 확률이 매우 낮다.
3) Voluntary response : 특정 집단이 자발적으로 설문에 참여하는 경우
ex) CNN 사이트에서 하는 기습 서베이 : CNN에 특정 시간에 접속하는 사람들은 대상으로 하므로 전체 모수에 대한 유의미한 결과를 내포하기 어렵다.
편향의 예 : 1936년도 미국 대선을 앞두고 한 매체에서 대대적인 설문조사를 벌였다. 표본은 240만명의 사람들이었으며, 공화당 대표가 승리할 것으로 예측하였다. 하지만 실제 투표에서는 민주당 후보가 62%의 득표율을 기록하며 승리하였고, 현재 이 설문조사는 편향된 표본의 대표적인 예로 인용되고 있다. 실제로 이 조사의 대상은 대부분 상류층(전화 소지자, 차량 소지자)였고, 이 시기가 대공황이었다는 점이 간과되었다. 이 매체는 이후 폐간되었다고 한다.
3. Sampling Methods
3.1) Simple random sample(단순임의추출법) : each case is equally likely to be selected
3.2) Cluster Sample(군집추출법) : divide the population clusters, randomly sample a few clusters, then sample all observations within these clusters
3.3) Stratified sample(층화추출법) : divide the population into homogenous strata, then randomly sample from within each stratum
3.4) multistage sample : divide the population clusters, randomly sample a few clusters, then randomly sample within these clusters.(Cluster Sample + Simple Random Sample)
4. Experimental Design
1. Principles of Experimental Design
1.1) Control : compare treatment of interest to a control group
1.2) randomly assign subjects to treatments
1.3) replicate : collect a sufficiently large sample, or replicate the entire study
1.4) block : block for variables known or suspected to affect the outcome
explanatory variables(factors) : conditions we can impose on experimental units
blocking variables : characteristics that the experimental units come with, that we would like to control for
respose variable : outcome
* placebo : fake treatment
* blinding : experimental units don't know which group they're in
* double-blind : both the experimental units and the researchers don't know the group assignment
5. Random Sample Assignment
1. Random Sampling : Each subject in the population is equally likely to be selected, and the resulting sample is likely representative of the population. Subjects are selected for a study.
2. Random Assignment : occurs only in experimental settings, where subjucts are being assigned to various treatments. samples exhibit slightly different characteristics from one another. Through random assginment, we ensure that these different characteristics are represented equally in the treatment and control groups.
=> Random assignment allows us to make causal conclusions based on the study.
*Confounding Variable(Confounder) : 설명 변수 외에 실험에 영향을 미칠 수 있는 변수들, sample assignment에서는 해당 변수들을 적절하게 배분한다.
1. Random Assignment + Random Sampling : 실험을 통해 인과관계를 파악할 수 있고 결과를 일반화할 수 있다. 하지만 완벽한 실험은 설계 및 시행이 매우 어렵다.(특히 대상이 인간이라면)
2. Random Assignment + No Random Sampling : 위의 실험 방법이 실현가능성이 매우 낮으므로, 대학이나 연구기관에서 설문조사 대상을 모집하는 것이다. 이 방법은 Random sampling은 아니지만, Random Assignment를 실행한 경우이다. 이 경우에는 실험을 통해 인과관계를 파악할 수 있지만, 이 인과관계는 설문조사한 집단에만 적용이 가능하며, 일반화될 수 없다.
3. No Random Assignment + Random Sampling : 우리가 일반적으로 수행하는 Observational Study이다. 변수간의 상관관계를 파악할 수 있고, 일반화될 수 있다.
4. No Random Assignment + No Random Sampling : Unideal Observational Study로, 실험을 통해 알아낸 변수들의 상관관계가 일반화될 수 없다. (샘플 집단에만 적용 가능)
6. R Assignment
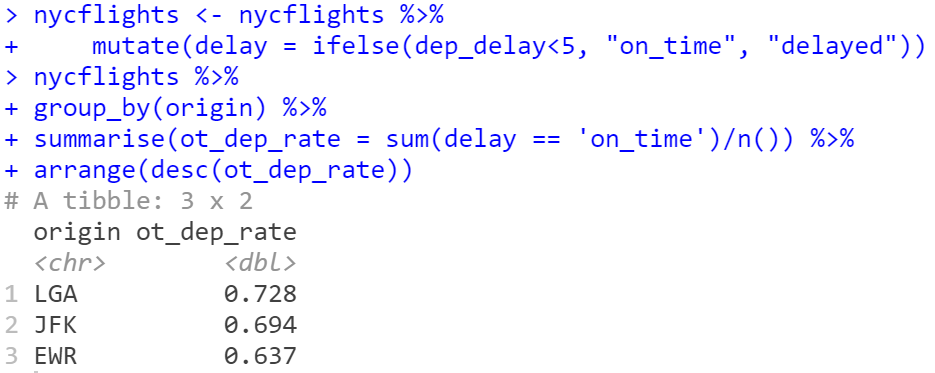
*piping(%>%) : Operator의 한 종류합니다.
?(function name) : 함수에 대한 정보를 Display합니다.
* Error
R Studio에서 devtools 패키지를 설치하는 과정에서 오류가 발생했습니다. callr과 관련된 업데이트 메시지였는데요, 구글링을 통해 여러가지 방법을 시험해본 결과 Rtools를 업데이트 하면 해결되는 것을 확인했습니다. 아래 사이트에서 recommended 버전(Rtools35)를 다운받아 설치하시면 됩니다.