12월부터 5개월간 정글 교육이 끝나고 7월 초까지 약 2달 반 남짓의 취준 생활을 하며, 총 9개의 회사의 채용전형을 경험했다. 교육이 끝난 후 배운 것들을 잘 정리하고 취업 준비하겠다는 생각이 무색하게, 수료 후 바로 다음주부터 취업 전형이 진행되어 면접 준비하랴 배운 것들을 정리하랴 정신없는 기간이었다.
우선 초반 몇 개의 면접을 보면서 느낀 점은, 공부하는 것과 면접을 보는 것은 너무나도 다르다는 것이다. 배웠던 내용도 중요하지만 면접을 위해 준비해야할 필수적인 것들이 있었고, 이걸 몰랐던 나는 면접을 보며 터득해야 했다. 처음 몇 개의 면접 때 대답하지 못했던 것들을 생각해보면 지금도 부끄럽기만 하다. 혹시나 정글 수료 후 면접을 준비중이라면, 아래 내용을 꼭 읽어보는 것을 추천한다. 스스로 공부가 부족하다고 느꼈던 DB나 네트워크 분야도 면접을 진행하며 조금이나마 채울 수 있었고, 회사에서 내주는 과제들을 수행하며 테스트 코드나 디자인 패턴에 대해서도 공부할 수 있었다.
SW사관학교 정글이라는 과정은 정말 만족스러웠지만, 목표는 취업인 만큼 결과도 무척이나 중요했다. 이전에 다니던 회사는 산학장학생으로 합격한 터라 취준이 생소한 나에게 취업 과정의 감정들은 참 낯설었다. 특히 처음 6개의 회사에서 탈락하는 와중에 동기들의 합격소식을 하나 둘씩 들으며, 자신감이 조금씩 떨어짐과 동시에 초조함을 느꼈다. 친구들 중에 1년 넘게 취업준비를 하는 친구가 있었는데, 도대체 어떻게 버텼을까라는 생각이 들었다.
아무튼 이런 과정들을 거쳐 최종적인 결과는..! 사실 지금도 잘 믿기지가 않는다. 스타트업 1곳과 '네카라쿠배' 중 2곳에 최종 합격했다. 이상하게도 3개 회사 모두 떨어질 것이라고 생각했는데 붙어서 신기했다. 모든 과정이 끝나고 원하는 목표를 이루고 나니 꿈만 같았고, 지금 생각은 부족한 나를 받아준 회사에서 열심히 일해야겠다는 생각뿐이다 :)
결론
0. 이력서 작성은 피드백을 꼭 받아보고, 코딩테스트는 꾸준히 준비해야 한다.
1. 면접 관련 질문은 한번은 꼭 읽어봐야 한다. (교육과정 정리 + 면접질문 공부 + 프로젝트 정리 필요!)
정말 믿기지 않지만, 마지막 프로젝트가 끝나고 이력서를 제출하는 것으로 137일간의(12월 7일 ~ 4월 22일) SW사관학교 정글 일정이 끝났다. 퇴사하느라 정신없이 입소했을 당시에는 정말 추운 겨울이었는데, 어느새 여름이 느껴진다. 기분이 복잡미묘하다. 취업에 대한 걱정과 사람들과 헤어지는 것에 대한 아쉬움. '드디어 해냈다'라거나 '정말 잘 끝냈다' 같은 기쁜 감정은 거의 없다는게 이상하다.
4달 반정도의 기간을 뒤돌아보면, 처음엔 정말 당황스러움의 연속이었지만 성공적으로 모든 게 끝났다는 것이 놀랍기만 하다. 나름 python을 공부한다고 회사 끝나고 공부하던 시절을 되돌아보면, 어떻게 공부해야 하는지, 어떤 것들을 공부해야 하는지 전혀 가늠이 잡히지 않던 시절이었다. 실제 들어왔을 때 Computer Science는 어떤 과목들을 배우는지 알 수 있었고, 모든 걸 다루진 못했지만 핵심 과제들을 꽤나 깊게 훑어볼 수 있었다.
이별에 대한 아쉬움만 제외하면 사람, 타이밍, 교육 모든 것이 완벽했던 시간이었다. 커리어 전환을 꿈꾸던 나에게 완벽한 기회였고, 다양한 분야의 사람들과 함께할 수 있는 기회였으며, 운영진 뿐만 아니라 서로에게 정말 많은 것을 배운 기회였다. 이 글을 빌어 운영진분들께 다시 한번 감사하다고 말씀드리고 싶다.
중요한 건 이제부터인것 같다. 사실 5개월이란 시간은 지금 생각해보면 사람이 바뀌기엔 너무나도 짧은 시간(할 땐 엄청 긴 것 같이 느껴졌지만)이다. 들어올 때는 5개월동안 열심히 해서 컴퓨터 전공한 사람과 비슷한 정도의 지식을 얻는 것이 목표였지만, 내가 얻은 가장 큰 것은 방향성과 습관, 할 수 있다는 자신감, 나와 함께 앞으로 나아갈 친구들인 것 같다. 공부의 방향성을 잡을 수 있게 되었고, 하루 온종일 시간을 쏟아 문제를 해결해나가며 할 수 있다는 자신감을 얻었고, 모르면 서로 물어보며 같이 성장할 친구들이 생겼다. 아직 많이 부족하지만, 할 수 있을 것 같다는 느낌(장병규 의장님은 효능감이라고 표현하셨다)을 가지고 계획을 잘 세우고 앞으로 나아가야겠다.
AWS에 여러명이 원격으로 접속을 하려다보니 PEM키를 공유하는 것보다 아이디 비밀번호로 접속하는 것이 더 쉬울 것 같아서 시작하게되었다. (보안성이 떨어지니 주의)
기존에 PEM 키를 가지고 있다면 아래와 같이 pem키를 가지고 명령어를 입력하여 접속해야 한다.
ssh -i ./final.pem ubuntu@[AWS IP주소]
우선 pem 키를 사용하여 ubuntu에 접속하자. 위의 명령어를 입력하여 접속하면 디렉토리가 홈으로 되어있을 것이다. 아래의 흐름을 따라가보자.
1. 경로 이동하기
cd ..
cd ..
cd etc
cd ssh
를 입력하여 root 디렉토리의 etc/ssh 폴더로 이동한다.
2. 파일 수정하기
sudo vim sshd_config를 입력하여 파일을 아래와 같이 수정한다.
3. root계정으로 swich하여 신규 계정 만들기
sudo su root
adduser "신규 계정 이름"
이후 아래와 같이 생성을 완료한다.
4. 권한 부여하기
sudo visudo를 입력한 뒤 아래와 같이 새로운 user(server)에 모든 권한을 부여한다. 다 작성하고 Ctrl-X를 누른 뒤 [Different-name = yes] → [파일명 뒤에 .tmp 삭제] → [overwrite = yes] 를 순서대로 수행하면 된다.
5. 재시작하기
sudo service ssh restart
6. 접속하기
위와 같이 특정 명령어를 입력해서 서버에 접속하고 싶으면 home 디렉토리의 ./bashrc(혹은 ./zshrc)같은 파일을 아래와 같이 편집하면 된다.
141개의 Test들을 통과하고 드디어 Pintos의 마지막 관문인 File System에 도착했다.
다음과 같은 4개의 과제가 우릴 마주한다. 또 다시 '도대체 뭐하라는거지?' 라는 생각이 든다.
간략한 과제 내용은 아래와 같다.
0. FAT File System : 과제마다 다를 수 있지만, 우리는 FAT 방식으로 File System을 구현하라는 과제를 받았다. 실제 리눅스 등에서는 Multi Level Indexing으로 구현되어있다고 한다. (FAT 방식이 훨씬 쉽다고 한다.)
1. Extensible files : 현재 핀토스의 모든 파일들은 기존 할당된 크기에서 유동적으로 파일 크기를 키울 수 없다. 기존 할당된 크기보다 더 쓰더라도 유동적으로 파일의 크기가 늘어나도록 변경하라. + System Call
2. Subdirectories : 현재 핀토스는 무조건 루트 경로에서 모든 일을 수행한다. 루트의 하위 경로들도 만들 수 있도록 변경하고, 바로가기(Soft Link)를 구현하라. + System Call
3. Buffer cache : 현재 핀토스에서는 Disk에서 읽은 데이터를 물리메모리에서 제거하는 경우 Swap Disk로 보내거나 Disk에 바로 써버린다. 이런 경우 접근하려고 할 때 다시 disk_read를 해야하므로, 시간이 오래 걸린다. 따라서 자주 쓸 것 같은 데이터는 물리 메모리에 Cache를 만들어 놓고 여기다 넣는다.
4. Remaining miscellaneous items : Extra
수정 파일 : filesys/filesys.c, filesys/fat.c, filesys/file.c, filesys/inode.c, userprog/syscall.c
Project 4 - 개념
1. FAT
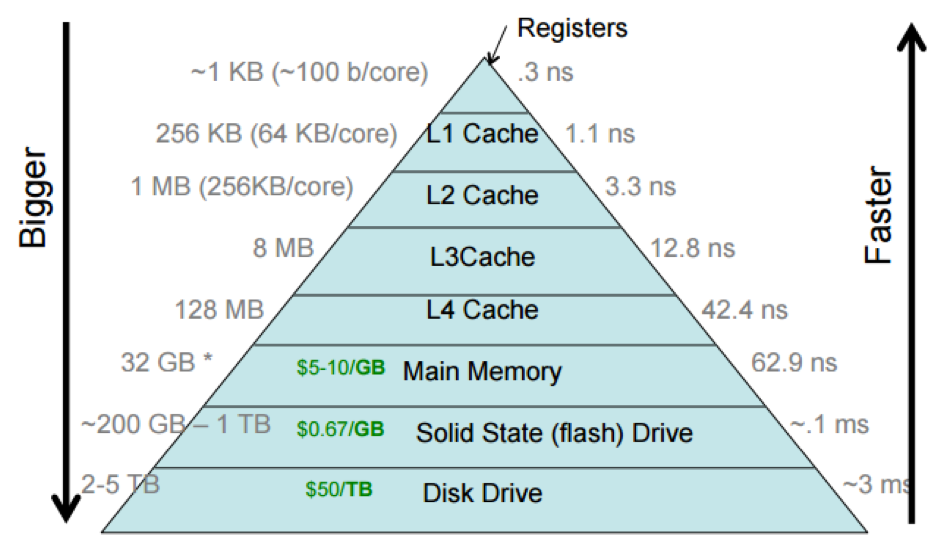
컴퓨터는 아래와 같은 하드웨어 구조를 가지고 있다. 아래 있는 계층은 바로 위의 계층의 캐시 역할을 한다.
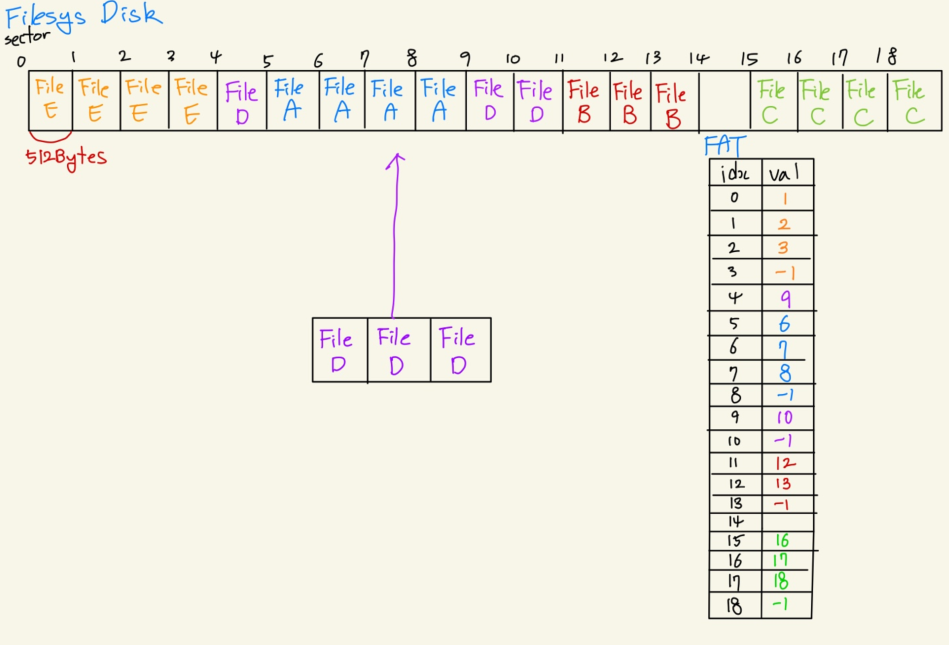
이번 프로젝트를 통해 다룰 메모리 공간은 맨 아래에 있는 Disk Drive(SSD 포함)이다. Disk 공간은 아래와 같이 512Byte의 Sector 단위로 나눠져 있다. (자세한 내용은 disk.c 참고) 기존 Pintos에서는 free map을 활용하여 disk를 연속적인 sector 단위로 관리한다. 예를 들면, 1024byte의 데이터를 쓴다고 하면 반드시 sector 0, 1, 2, 3에 쓰는 방식이다. 이런 식으로 관리를 하면 아래 그림과 같이 외부 단편화(External Fragmentation)가 발생한다. 공간은 3개 있지만 3개짜리 파일이 들어갈 공간이 없는 것이다.
이런 외부 단편화의 문제를 해결하기 위해, FAT(File Allocation Table)를 활용한다. FAT 방식은 빈 Sector들을 찾아 데이터를 기록한 뒤, 파일들이 연결된 정보를 File Allocation Table에 기록해놓는다. 아래의 그림을 보면, 3개의 빈 Sector가 있는데 파일 크기가 3인 파일을 기록할 수 없었던 기존 방식과는 달리 3개의 빈 Sector가 있다면 File D를 기록할 수 있다.
FAT 방식은 File Allocation Table이라는 표를 만들어서, 파일이 기록된 섹터들의 정보를 Chain 형태로 저장해놓은 것이다. 아래의 File D가 저장된 공간을 보면 4 - 9 - 10번 Sector에 순서대로 저장되어 있다. 이 정보를 FAT에 기록된 형태를 보면, FAT[4] = 9, FAT[9] = 10, FAT[10] = -1이 기록되어 있다. 4번 섹터의 다음 섹터는 9번 섹터이고, 9번 섹터의 다음 섹터는 10번 섹터이며, 10번 섹터가 해당 파일의 마지막 섹터라는 정보를 나타낸 것이다. (마지막 섹터에는 -1 혹은 구분할 수 있는 값을 넣어놓는다.)
구현할 때 생각해야 할 점은 FAT 자체도 disk에 저장되어야 한다는 점이고, 이 부분은 침범되어서는 안된다는 것이다. 그래야 컴퓨터를 끄고 킬 때도 파일에 대한 정보가 남아있을 것이다.
지금은 FAT의 기본 단위(Cluster)가 1 sector와 같다고 가정했지만, 임의의 갯수의 sector를 하나의 cluster로 묶어서 관리하는 것도 가능하다.
2. Inode
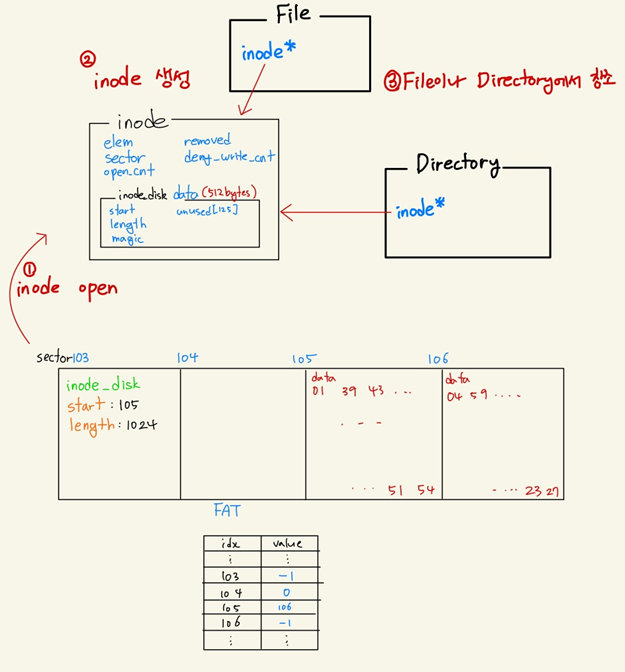
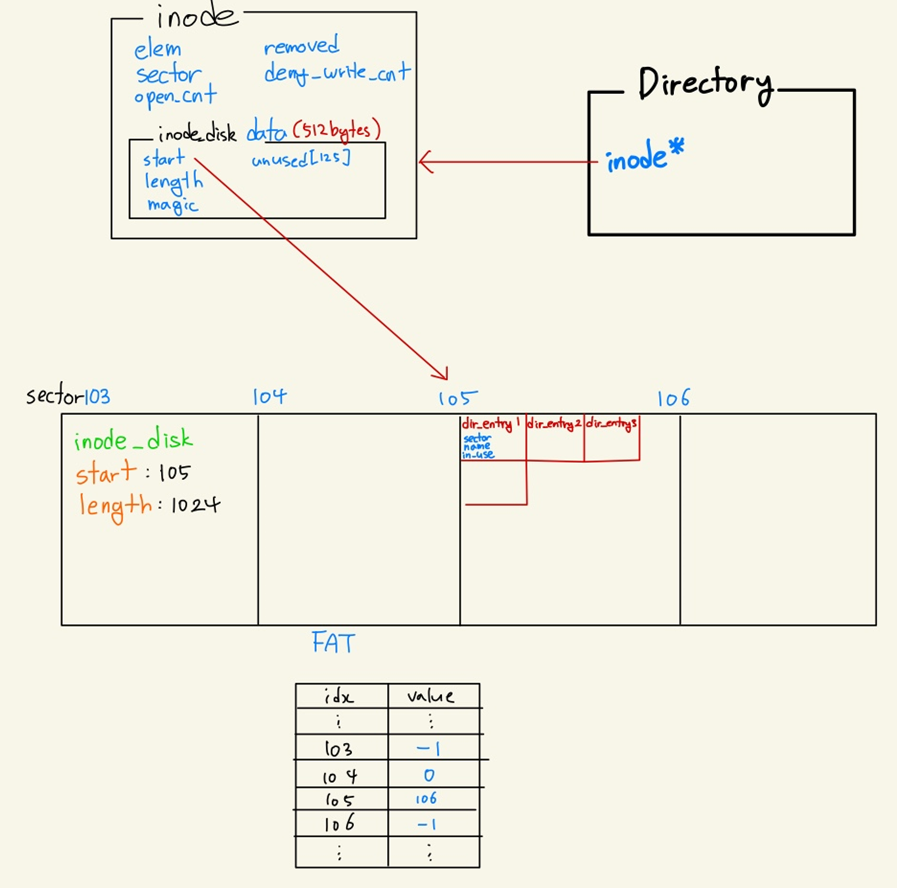
Inode란 파일이나 디렉토리에 대한 metadata를 가지고 있는 고유 식별자이다. 파일과 디렉토리는 모두 inode를 하나씩 가리키는 inode 포인터를 가지고 있다. inode 구조체는 파일이나 디렉토리를 열 때 발생하는 inode_open() 함수 실행 시에 생성되며, 열리지 않았을 때는 inode_disk인 상태로 Disk에 저장되어 있다. inode는 메타데이터 정보를 담고있는 512Byte의 inode_disk를 하나씩 가지고 있고, inode_disk는 실제 파일에 대한 메타데이터를 포함하고 있다. 실제 파일의 경우 아래와 같이 디스크에 저장되어있다.
* Metadata : 속성을 설명하는 정보
ex : 글의 길이, offset ...
이제 inode 구조체의 원소들을 하나씩 살펴보자.
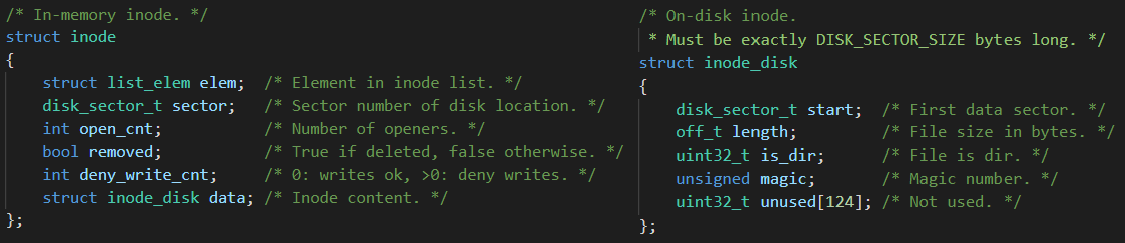
Inode
1. elem : inode를 생성하면 open_inodes라는 list에 추가해주기 위해 필요한 요소.
2. sector : inode_disk가 저장되어있는 disk의 sector를 나타낸다.
3. open_cnt : inode가 열려있으면 닫으면 안된다. 이를 관리해주기 위해 변수를 생성하여 카운팅한다.
4. removed : 삭제해도 되는지 여부를 저장한다. inode_remove()를 참조.
5. data : 디스크에 저장된 메타데이터 정보를 물리메모리에 올려놓은 것이다. 매번 disk에 참조할 수 없기 때문에 물리 메모리에 올려놓고 사용하며, 더이상 필요가 없어지면 inode_close()시에 다시 disk에 write back한다.
Inode Disk
1. start : 파일의 inode인 경우 파일의 실제 내용, 디렉토리의 inode인 경우 directory entry들이 저장되어 있는 disk의 sector 번호를 나타낸다.
2. length : 저장된 공간의 길이를 나타낸다(Sector 단위)
+ : 나머지 공간은 sector size인 512byte를 맞춰주기 위해 넣어둔 데이터이다. (Disk Write/Read 시에는 반드시 512byte 단위로 해야한다. 이 공간을 잘 활용할 수 있으면 좋다.
3. File
File Open을 하면 생성되는 파일 구조체이다. 코드 상의 inode는 File의 inode를 가리키고 있으며, 이 inode 안에는 File Data에 대한 Metadata가 저장되어있다(inode_disk). 하나하나 살펴보자.
1. inode : 파일 데이터에 대한 정보를 포함하고 있다.
2. pos : 파일을 읽거나 쓸 때 처음부터 다 읽거나 쓸 필요는 없다.
3. deny_write : 읽기 전용 파일을 나타내기 위해 사용하는 변수.
4. Directory
디렉토리도 파일이다. 자세히 보면 구조체 내에 inode가 동일하게 위치하고 있는 것도 볼 수 있다. 다만 File에 Data가 있었다면 Directory에는 directory_entry들이 있을 뿐이다. 기억해야 할 것은 directory를 조회하기 위해 dir 구조체를 따라 들어가면 inode가 있고, inode 안의 inode_disk에 기록된 sector를 따라가보면 dir_entry들이 기록되어있는 것이다. 내가 원하는 이름을 가진 dir_entry를 찾고, 이녀석이 가리키는 sector로 다시 가면 내가 원하는 데이터가 있을 것이다.
Directory, Directory_entry 구조체에 대해 알아보자.
Dir
1. inode : 하위 dir_entry들을 저장하고 있는 sector를 찾아가기 위해 이용한다.
2. pos : 어디까지 읽었는지 확인한다.(readdir()구현 시 사용)
Dir Entry
1. inode_sector : dir_entry의 정보를 담고있는 sector를 가리킨다.
2. name : 파일이나 디렉토리의 이름이다.
3. in_use : lookup 할 때 사용할 정보이다. 이 위치에 dir_entry가 저장되어있는지에 대한 정보를 나타낸다.
Project 4 - 구현
0. FAT
1) fat.c에 기본적인 내용(boot 시 fat를 load하고 종료 시 fat를 write back하는 기능)은 구현되어있다.
2) 우리가 해야할 일은 fat 테이블을 업데이트하고, 컴퓨터를 끄고 키더라도 동일한 위치에 저장되어있도록 보장하는 것이다.
3) Root Directory는 format할 때 만들어줘야 한다.
4) Cluster to sector 함수를 잘 생각하고 만들어야 한다. fat table도 disk에 저장되어야 한다는 점을 꼭 기억하자. 이부분을 아예 없다고 생각하고 Cluster to sector을 만들 것인지, 아니면 있다고 생각하되 데이터가 이미 기록되어있음을 File Allocation Table에 기록할 것인지를 선택해야한다. Sector가 들어가야 하는 위치에 Cluster가 인자로 들어가거나, 반대로 된 경우가 없는지 반드시 체크하자.
1. Extensible Files
1) FAT를 구현했다면 이건 쉽다. inode_create이나 Write/Read시에 내가 잘 만들어놓은 Chain을 따라가게 하면 된다. 만약 File length를 늘린다고 하면, 새로운 chain을 하나 추가하여 기록한다.
2) File length가 늘어난다고 하면 inode_disk에 이 data를 업데이트해줘야 하며, sector_size와 file_length는 다르다는 점을 인지하자.
3) inode_disk는 data의 길이에 포함되지 않는다.
2. Subdirectories
1) 입력을 받은 뒤 parsing하여 효율적으로 인자를 전달하는 것이 생각보다 까다롭다. 예외처리와의 싸움일 것이다. 인자가 비어있거나, 존재하지 않거나, 지우면 안되거나 등등을 고려해야 한다.
2) .과 ..은 기본적으로 directory에 추가해주는 것이 좋다.
3) 파일을 열었다면, 반드시 잘 닫아줘야 한다. open_cnt 때문인데, 일반적으로 open_cnt가 0일 때 inode의 사용이 끝났음을 인지하고 disk에 write back해주기 때문이다. 그렇다면 open_cnt가 언제 증가하고 언제 감소하는지에 대해 이해하고 있어야 한다. inode_open(dir_open이 아님)이나 reopen시에 증가하고, inode_close 시에 감소한다. inode_open함수는 어디서 사용하는지 확인해보자.
4) directory인지, file인지 확인이 필요할 때가 있다. Syscall마다 이를 구분할 필요가 있는 경우에는 처리해준다.
5) directory도 open할 수 있다. open된 directory는 제거하면 안된다.
3. Persistence
1) 위의 과정을 제대로 했다면 종료 후 다시 Booting을 하더라도 데이터가 잘 기록되어있어야 한다.
2) 위에서 말했던 open_cnt를 잘 고려하지 않았거나, root directory를 boot 시마다 갱신해주는 것은 아닌지 확인해보자
Project 4 - 후기
드디어 192개의 모든 Test를 안정적으로 통과하는 것을 확인했다. 길고 길었던 Pintos, 잠도 잘 못자는 경우가 다반사였지만, 많은 것을 느낄 수 있었던 기간이었다. Linux에 대한 기본적인 이해도 할 수 있었고, 아예 모르는 것에 대한 두려움을 많이 줄일 수 있었다. Pintos를 처음 시작하는 사람이라면, 처음에 진짜 아무것도 몰라서 막막하더라도 조금씩 이해하다보면 끝낼 수 있다고 말해주고 싶다.
100개 가까운 테스트를 통과하고 Project3 - Virtual Memory에 도달하여 매우 기쁘지만, 아래와 같은 문구가 Project 3에서 우릴 기다리고 있다. 이제까지 제대로 만들었길 기도하자. (이번에도 도대체 뭐하라는거야 가 기다리고 있으니 너무 기대하지 말자.)
"You should take care to fix any bugs in your project 2 submission before you start work on project 3, because those bugs will most likely cause the same problems in project 3."
간략한 과제 내용은 아래와 같다.
0. 프로그램을 실행하려면, 실행에 필요한 데이터(Ex : Code)를 물리메모리(RAM)에 올려야 한다. 지금은 실행 전에 load(), load_segment()라는 함수에서 실행에 필요한 모든 데이터를 물리메모리에 올려버리고 있다. 이 방식은 매우 비효율적이므로, 모든 데이터를 다 올리는 대신에 실행 중에 해당 데이터가 필요하게 되면 그 때 물리메모리에 올리는 방식으로 변경하자.(Lazy Load)
1. 현재 스택은 한개의 Page만 할당되어 있고, 한 Page 이상의 데이터를 저장하는 경우는 고려되지 않았다. 한 Page를 넘는 데이터를 저장하더라도 유동적으로 늘릴 수 있도록 변경하라.(Stack Growth)
2. 프로그램을 많이 실행하거나, 많은 데이터를 저장하다보면 물리메모리가 가득 차서 무언가를 빼내야 하는 상황이 발생한다. 이를 고려하여 임시로 저장하는 공간인 Swap Disk를 만들고 빼낸 데이터는 잠시 이 곳에 넣어두기로 한다. Swap Disk는 갈 곳이 없는 것들만 넣어두는 것이고, File에서 불러온 데이터는 다시 File에 쓰면 된다.
Project 3 - 개념
Project 3을 진행하기 위해서는 아래의 내용들을 이해해야 한다.
우선 전체적인 그림을 한번 알아보자.
Pintos 내에서 생성되는 모든 Thread는 각자 독립된 가상주소공간(0 ~ KERN_BASE)을 가진다. KERN_BASE가 0x8004000000이므로, 각 프로세스는 550Giga Byte의 주소공간을 표현할 수 있다.(하지만 실제로 사용되는 공간은 매우 작다.) 각자의 Thread가 KERN_BASE 이하의 특정 주소의 데이터를 읽으려고 하면, Thread에 저장되어있는 Page Table에서 이 주소를 실제 물리 주소로 변경한 뒤 실제 물리주소에서 데이터를 읽어오게 된다.
0) Virtual Address
위에서 말한 가상주소공간은 Thread별로 할당된 것이며, 각각의 Thread는 이 가상주소공간만큼의 크기를 모두 쓸 수 있을 것만 같은 착각을 가진다. 하지만 사용자가 0x400000에 data를 Write하라고 명령을 내리더라도, Thread는 이 주소를 실제 물리주소로 변환한 뒤에 그곳에 Write한다. 이렇게 함으로써 OS는 사용자가 만든 Thread가 실수를 하더라도 다른 Thread의 공간을 침범하는 것을 막을 수 있다.
1) Page
가상 공간의 Data에 대한 정보를 저장하고 있는 구조체이다. 모든 물리메모리공간은 Page(1024Bytes)단위로 관리된다. Page 내에는 어떤 인자들이 있는지 확인해보자.
1. operations
Page는 anon, uninit, file이라는 3가지 Type이 존재한다. 이유는 Stack이나 Code, 등 데이터의 종류에 따라 다른 방식으로 처리해줘야하기 때문이다. 아래와 같이 type별로 swap_in, swap_out, destroy 시 실행해야 하는 함수를 별도로 저장해두고 실행한다.
* Swap in : 해당 Page를 물리 메모리(RAM)에 Load하는 행위
* Swap Out : 해당 Page를 물리 메모리에서 제거하는 행위. 돌아갈 곳이 없는 Page는 Swap Disk에, Disk에 다시 써도 되는 녀석들은 Disk에 Write하는 행위를 해줄 것이다.
* Destroy : 해당 Page를 제거하는 행위
2. va : 데이터가 저장된 가상주소의 시작점이다.
3. frame : page와 matching된 frame을 가리킨다.
2) Frame
: 물리공간에 대한 정보를 가지고 있는 구조체이다. Page Table에는 Page의 va : Frame의 kva가 매칭되어 있다.
1. kva : 실제 물리주소이다. (실제 저장되는 물리주소는 (kva - KERN_BASE)이긴 하다.)
3) Page Table
모든 Thread는 각각pml4라는 이름의Page Table을 가지고 있다. (thread_create()함수의 pml4_create() 참고) Page Table에는 va : kva로 mapping이 되어있기 때문에, 가상주소에서 물리주소로의 번역이 가능하다. Mapping 정보를 확인하기 위해 va를 가지고 Page Table을 찾았는데, 매칭되는 kva가 없다면 Page Fault가 발생한다.
5) Page Fault
사용자가 원하는 임의의 가상 주소에 접근하려고 했을 때, thread는 해당 주소가 포함된 Page의 시작 주소(va)를 찾은 뒤(=pg_round_down(va)), 이것에 매칭된 물리주소(kva)가 있는지 Page Table에서 찾는다. 만약 matching 된 정보가 없다면 Page Fault를 발생시킨다. Page Fault Handler에서 Page Fault에 대한 처리를 하면, 해당 가상 주소는 이제 접근이 가능하게 된다. 현재는 Page Fault Handler에서 아무런 조치를 하지 않는다. 이런 경우 외에도, 읽기 전용인 페이지에 Write를 하려고 해도 Page Fault가 발생한다.
Page Table에 va : kva 매핑하는 작업은 install_page(), 매핑된 정보를 제거하는 작업은 clear_page()를 참고하자.
6) Bitmap
메모리공간의 사용가능여부를 나타내는 Bit들의 집합이다. 1이면 사용중, 0이면 비어있음을 나타내도록 사용할 수 있다. bitmap.c 파일에 자세히 나와있다.
7) MMAP
사용자가 명시적으로 파일의 내용을 물리메모리에 올리도록 요청하는 System Call이다. 사용자가 요청하는 바는 디스크에 있는 파일의 데이터를 물리메모리에 올리라는 것이나, 당장 사용하지 않을 데이터를 모두 한정된 물리메모리에 올려놓는 것은 비효율적이기 때문에 load_segment와 마찬가지로 페이지 정보만 등록해놓고 필요할 때 물리메모리에 Load하기로 한다.
8)Supplemental Page Table
Lazy Load를 구현하려면, Page에 대한 정보(어디서 가져와야 하는 데이터인지, 어떤 데이터인지..)를 어디엔가 등록해놓은 뒤 Page Fault가 발생하면 이 정보를 찾아 메모리에 Load해야 한다. 따라서 Page에 대한 정보를 저장해놓을 공간이 필요한데, 이게 SPT다. SPT에서 Page에 대한 정보를 찾는 시간을 최소화하기 위해 Hash Table을 사용한다.
9) Swap Table
위에서 설명했듯이, 물리메모리가 가득찼을 때 기존에 있던 Page들 중 하나를 밖으로 빼내고 새로운 Page를 넣어야 한다. 새로 물리 메모리에 Load되는 Page는 Swap In 된다고 하고, 기존에 물리메모리에 올려져 있었으나 꺼내지는 Page는 Swap Out 된다고 부른다.
위에서 살펴봤듯이, Page의 종류는 3가지가 있다. Uninit, Anon, File이다. Uninit Type은 초기화되지 않은 Page로 Page 정보는 생성되었으나 사용자가 해당 Page에 접근하지 않았다는 것을 의미한다. 따라서 물리메모리에 올라가있는 페이지가 Uninit일수는 없다. File Type은 mmap된 Page이다. File Type은 Swap In될 때 disk에서 직접 읽어오면 되고, Swap Out될 때는 직접 Disk에 다시 쓰면 된다. Anon Type은 Stack, Text 등을 포함한다. Anon Type은 Swap Out될 때 디스크에 다시 돌아갈 곳도 없고, 무작정 제거하면 다음에 접근할 수 없다. 따라서 물리 Disk에 Swap Disk란 공간을 별도로 할당해서 이곳에서 Swap In/Out되는 Anon Type Page들을 관리한다.
Swap Table은 Swap Disk의 할당 정보를 포함하고 있는 Table이라고 생각하면 된다. bitmap을 사용하여 Swap Table을 구현할 수 있다.
* 교체 Policy
물리메모리가 가득 차서 현재 Load된 Page들 중 하나를 빼낼 때 어떤 녀석을 빼낼 것인가에 대한 정책이다. FIFO도 가능하고, LRU 등 다양한 교체 알고리즘이 있다. Test Case들은 FIFO 방식으로 구현해도 시간은 충분했다. (컴퓨터 환경에 따라 조금씩 다를 수 있다.)
* Accessed and dirty bit
File Type Page가 Swap Out되는 경우를 생각해보자. 만약 데이터를 사용자가 읽기만 하고 변경하지 않았다면, 굳이 disk에 다시 써줄 필요가 없다. 고맙게도 CPU는 사용자가 특정 Page를 수정했다면 dirty bit를 1로 바꿔주는데, 이를 확인한 뒤 Disk Write back을 할지 말지 결정한다.
* Copy On Write
기본적으로 fork 구현 시 frame을 모두 새로 할당하여 복사해주었을 것이다. 이런 경우도 마찬가지로 비효율을 초래할 수 있다. 따라서 fork할 때 자식은 부모가 할당한 물리 메모리 공간을 가리키게 하되, writable을 0으로 해준다. 읽는 것은 가능하지만, 무언가 쓰려고 하면 Page Fault가 발생할 것이고 이 때 새로 물리메모리 공간을 할당해서 복사를 진행한다. writable을 0으로 모두 할당할 것이지만, 기존에 존재하던 Page의 writable여부도 반드시 저장해서 새로 물리공간을 할당할 때 update해줘야 한다는 것을 잊지 말자.
Project 3 - 구현
전체적인 그림을 한번 잡고 시작할 수 있다면 더 좋을 것 같다.(가능할진 모르겠지만) 위의 내용들을 이해했고 무엇을 해야할지 파악했다면, 구현하는건 조금이나마 더 수월할 것이다. 제대로 된 데이터가 Load되는지, Swap In/Out 된 데이터가 일치하는지 여부를 hex_dump()함수를 활용하여 직접 확인해보는 것을 추천한다.
(실제 구현은 root 여부를 확인하기 위해 Tree 구조체도 같이 전달하는 방식으로 구현했다. 특정 key를 삭제했을 때 root가 사라지는지 확인하는 과정이 꼭 필요하다.)
key X를 삭제하는 과정은 Tree의 root Node로부터 시작해서 X가 들어있는 노드를 찾는 것으로 시작한다. 삭제하는데 발생가능한 경우는 아래와 같이 크게 세 가지로 나눠볼 수 있다.
1. N이 Leaf Node인 경우
→ Node N의 key들에 대하여 for문을 돌며 확인한 뒤, X가 존재하면 삭제한 뒤 True를 return, 없다면 False를 return한다.
2. Node N 안에 key X가 있는 경우
a) key X의 선행 자식 Node Y가 최소 t개의 키를 가진다면, X의 선행키(Predecessor) K를 X와 바꾼 뒤, K를 삭제한다. 이후 아래 노드로 내려가며 X를 삭제한다.
ex) 아래 그림에서 key 16을 지우려는 경우이다.
1. 16의 선행자식 Node Y는 3개의 Key를 가지고 있으므로 t(2)개 이상을 만족한다. 따라서 선행키인 15와 교환한 다.
2. key X(16)를 지우러 내려간다.
b) key X의 후행 자식 Node Z가 최소 t개의 키를 가진다면, X의 후행키(Successor) K'과 X를 바꾼 뒤, 아래 노드로 내려가며 X를 삭제한다.
c) key X의 선행 자식 Node Y와, 후행 자식 Node Z 모두 t-1개의 자식을 가진다면, Node Y와 Z를 합치고(merge) X를 삭제한다.
선행키와 후행키란 ?
아래 그림의 Tree에서 key = 12를 삭제하려고 한다. 선행키와 후행키는 어떤 값인가?
* 선행키(Predecessor) : 특정 Key의 왼쪽 자식 노드를 root로 하는 서브트리(초록색)에서 가장 오른쪽에 있는 값 = 11
* 후행키(Successor) : 특정 Key의 오른쪽 자식 노드를 root로 하는 서브트리(초록색)에서 가장 왼쪽에 있는 값 = 13
3. Node N 안에 key X가 없는 경우
계속 X를 찾아 들어가야 하므로, 다음 살펴볼 Node C를 정한다. (Node N의 key 값을 기준으로 비교한 뒤 정한다.) 해당 Child Node가 t-1개의 자식을 가진 경우, 아래와 같은 두가지 경우가 있을 수 있다.
a) Node C 양 옆의 Node 중 t개 이상의 key를 가진 Node가 있는 경우
→ 하나의 key를 해당 Node에서 빌려온 뒤, 재귀적으로 C로 들어간다.(deleteNode(key x, Node C))
(Node C의 key 개수는 2t-2개가 된다.)
b) Node C 양 옆의 Node들이 모두 t-1개의 자식을 가진 경우
→ 양 옆 중 하나의 Node와 병합한 뒤, 재귀적으로 C로 들어간다.(deleteNode(key x, Node C)) 이 때, 두 Node를 가리키는 Child Pointer들 사이에 있는 key는 병합된 Node C로 같이 내려온다. (Node C의 key 개수는 2t-1개가 된다.)
※ 참고할 사항 ※
* 여기서도 삽입할 때 Split을 해주며 찾아내려간 것과 마찬가지로, 만약 Node N이 t-1개의 자식을 갖고있다면 옆의 Node와 Merge를 하거나 옆 Node에서 Key를 빌려서 충분한 key의 개수를 충족시킨 후 내려간다.
: 여기서부터 조금 복잡하다. 키를 루트에 삽입할 때 사용하는 함수는 insert(), insertNonfull(), split()이다. 우리가 깊이 고민해야되는 부분은 '임의의 노드가 이미 키를 2t-1개 가지고 있을 때, 어떻게 삽입해줘야 하는가' 이다. 우선 간단한 예시를 살펴보자.
아래 그림과 같이 최대차수가 4(최소차수 t = 2)인 트리의 루트에 키가 3개 들어있다. 새로운 키 1개(3)가 더 들어가면 어떻게 될지 살펴보자.
1. 키 삽입 시도
노드 한개에 들어갈 수 있는 키는 최대 3개이다.
2. 새로운 노드 생성 후 루트 노드로 지정
: 새로운 노드 s를 만들어 tree의 root로 지정하고, 기존 노드 r을 가리키게 한다.(삽입하려는 노드가 root가 아닌 경우에는 실행하지 않는다.) r의 isLeaf속성은 True로 바뀌어야 한다.
3. 기존 노드 Split
1. r의 가운데 key를 노드 s로 올려준다.
2. 새로운 노드 z를 만들고, r의 가운데 key 기준 우측 key값(t+1번째부터 2t-1번째까지)들을 모두 z로 옮긴다.
3. Split하려는 노드가 Leaf 노드가 아니어서 Child Pointer들을 가지고 있는 경우, r의 Child Pointer도 노드 z로 옮겨줘야 한다.
4. 각 노드들의 key 개수(key_num)을 업데이트한다.
4. 삽입 완료
: Split이 완료되면 기존 노드(r)와, 새로 생긴 2개의 노드(s,z)는 모두 t-1개의 키를 갖는다. 모든 노드들이 새로운 키값을 넣을 공간이 있으므로, 새로운 키(3)을 알맞은 위치에 넣어준다.
※ 참고할 사항 ※
1. 삽입하는 과정에서, 새로운 키는 항상 Leaf Node에 추가해야한다.
2. 트리는 항상 기존 존재하던 노드 기준으로 위(Upward)로 자란다.
3. root 노드인 경우는 별도의 작업으로 처리해줘야하기 때문에 insert()함수가 존재하고, root가 아닌 노드인 경우에는 insertNonfull()에서 처리한다.
4. 키를 삽입할 때 들어가야 할 자리(Leaf Node)를 찾기 위해 노드들을 탐색하며 내려가게 되는데, Leaf Node가 아니더라도 내려가는 과정의 모든 Node에 대해서 키의 개수가 2t-1개(최대)이면 split을 해줘야 한다. 이는 Leaf Node가 가득차서 Split을 할 경우에 다시 위로 올라가서 연산하는 것을 방지하기 위함이다.
5. 가득 찬 경우에는 split()을 하지만, 가득차지 않은 경우에는 split()을 진행하지 않는다.
Project 1에서는 Kernel 영역에서 쓰레드들을 생성하고 Scheduling을 제대로 수행하도록 만들었다. Project2에서는 사용자의 입력을 받아 원하는 작업을 수행할 수 있는 기능을 구현하고, 사용자의 명령을 Kernel 영역에서 실행해줄 System Call들을 만든다. 프로젝트를 완료하면, PINTOS에서 특정 파일을 실행시켜 원하는 결과를 얻을 수 있다.
* 이번 프로젝트는 System Call들을 구현하기 전까지 제대로 구현했는지 테스트를 통해 알아보기 힘들기 때문에, hex_dump()등의 함수를 잘 활용하자.
목표 : User의 입력을 받는 기능을 구현하고, User가 의도한 결과를 return하기 위해 Kernel 영역에서 수행되는 System Call들을 만든다.
Project 2 - 기본 내용
1. User Mode / Kernel Mode + User Stack
프로세스/쓰레드는 User Mode와 Kernel Mode를 왔다갔다하며 수행한다. User Mode는 사용자가 사용을 하는 영역, Kernel Mode는 사용자의 입력을 받아 Kernel 단에서 수행을 해주는 영역이다. User Mode에서 사용자가 입력을 하면 해당 입력 내용이 User Stack에 저장되고, Kernel Mode에서 입력 내용을 꺼내어 원하는 작업을 수행하게 된다. User Mode에서 사용자의 입력을 User Stack에 저장하는 작업을 여기선 Argument Stack이라고 부른다.
2. System Call
사용자(User)가 시스템의 Hardware 또는 관리가 필요한 기능들을 사용하고자 할 때 호출하는 함수이다. User Mode에서 System Call을 호출하면, Kernel Mode로 전환하여 해당 내용을 수행하게 된다. Pintos에서 작용하는 방식을 간단히 살펴보자.
사용자가 특정 파일을 열고자 open()이라는 함수를 호출한다. User Mode에서 해당 함수를 호출하면, lib/user 폴더에 있는 syscall.c에서 open()이라는 System Call이 실행되고, 이 함수는 현재 레지스터 상태들을 저장(User Mode 상태 저장)한 뒤 Kernel mode에서 userprog/syscall.c에 있는 open 함수를 수행한다. (초기에는 정의되어있지 않으므로 구현이 필요하다.) 해당 System Call을 수행한 결과값은 intr_frame의 rax에 저장되어 User Mode로 복귀하게 된다.
프로젝트 진행
1. User의 입력을 받는 기능을 구현한다.
argument_stack() 함수를 구현한다. 들어온 데이터를 parsing하여 word-align되도록 데이터를 자른 뒤, User Stack에 차곡차곡 쌓는다. 다 쌓고난 뒤 데이터 시작 위치를 rsi에, argument 개수를 rdi에 넣어주면 된다.
2. System Call들을 구현한다.
앞의 내용들을 다 구현하고 System Call을 구현하는 시점에 도달하면 이제 Test case들을 수행해볼 수 있어 한결 낫다. syscall_handler에서 switch문으로 어떤 System call을 수행해야하는지 구분해놓고, 각 system call 함수들을 구현하면 된다. 구현 시 어려운 함수는 fork(), wait(), exit()이었던 것 같다. fork()는 함수 실행 시 분기 흐름을 파악하기 어려웠고, wait(), exit()은 종료 시점을 판단하는 것과 종료 시 memory free하는 것이 어려웠다.
이번 프로젝트는 System Call을 완성하기 전까지 제대로 구현되었는지 확인할 수 없다는 점, 핀토스 내부 작동 방식을 파악해야한다는 점이 힘들었다.