Project 4 - File System
141개의 Test들을 통과하고 드디어 Pintos의 마지막 관문인 File System에 도착했다.
다음과 같은 4개의 과제가 우릴 마주한다. 또 다시 '도대체 뭐하라는거지?' 라는 생각이 든다.
간략한 과제 내용은 아래와 같다.
0. FAT File System : 과제마다 다를 수 있지만, 우리는 FAT 방식으로 File System을 구현하라는 과제를 받았다. 실제 리눅스 등에서는 Multi Level Indexing으로 구현되어있다고 한다. (FAT 방식이 훨씬 쉽다고 한다.)
1. Extensible files : 현재 핀토스의 모든 파일들은 기존 할당된 크기에서 유동적으로 파일 크기를 키울 수 없다. 기존 할당된 크기보다 더 쓰더라도 유동적으로 파일의 크기가 늘어나도록 변경하라. + System Call
2. Subdirectories : 현재 핀토스는 무조건 루트 경로에서 모든 일을 수행한다. 루트의 하위 경로들도 만들 수 있도록 변경하고, 바로가기(Soft Link)를 구현하라. + System Call
3. Buffer cache : 현재 핀토스에서는 Disk에서 읽은 데이터를 물리메모리에서 제거하는 경우 Swap Disk로 보내거나 Disk에 바로 써버린다. 이런 경우 접근하려고 할 때 다시 disk_read를 해야하므로, 시간이 오래 걸린다. 따라서 자주 쓸 것 같은 데이터는 물리 메모리에 Cache를 만들어 놓고 여기다 넣는다.
4. Remaining miscellaneous items : Extra
수정 파일 : filesys/filesys.c, filesys/fat.c, filesys/file.c, filesys/inode.c, userprog/syscall.c
Project 4 - 개념
1. FAT
컴퓨터는 아래와 같은 하드웨어 구조를 가지고 있다. 아래 있는 계층은 바로 위의 계층의 캐시 역할을 한다.
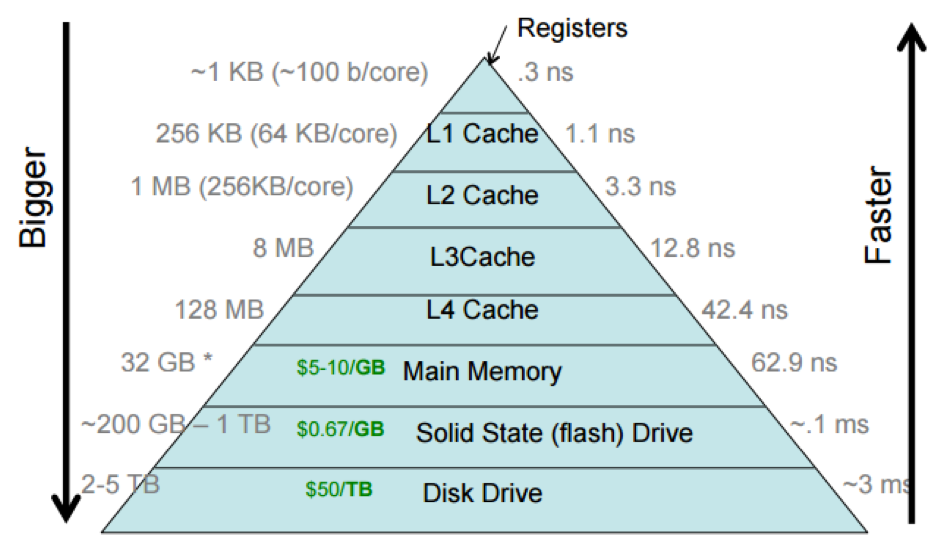
이번 프로젝트를 통해 다룰 메모리 공간은 맨 아래에 있는 Disk Drive(SSD 포함)이다. Disk 공간은 아래와 같이 512Byte의 Sector 단위로 나눠져 있다. (자세한 내용은 disk.c 참고) 기존 Pintos에서는 free map을 활용하여 disk를 연속적인 sector 단위로 관리한다. 예를 들면, 1024byte의 데이터를 쓴다고 하면 반드시 sector 0, 1, 2, 3에 쓰는 방식이다. 이런 식으로 관리를 하면 아래 그림과 같이 외부 단편화(External Fragmentation)가 발생한다. 공간은 3개 있지만 3개짜리 파일이 들어갈 공간이 없는 것이다.

이런 외부 단편화의 문제를 해결하기 위해, FAT(File Allocation Table)를 활용한다. FAT 방식은 빈 Sector들을 찾아 데이터를 기록한 뒤, 파일들이 연결된 정보를 File Allocation Table에 기록해놓는다. 아래의 그림을 보면, 3개의 빈 Sector가 있는데 파일 크기가 3인 파일을 기록할 수 없었던 기존 방식과는 달리 3개의 빈 Sector가 있다면 File D를 기록할 수 있다.
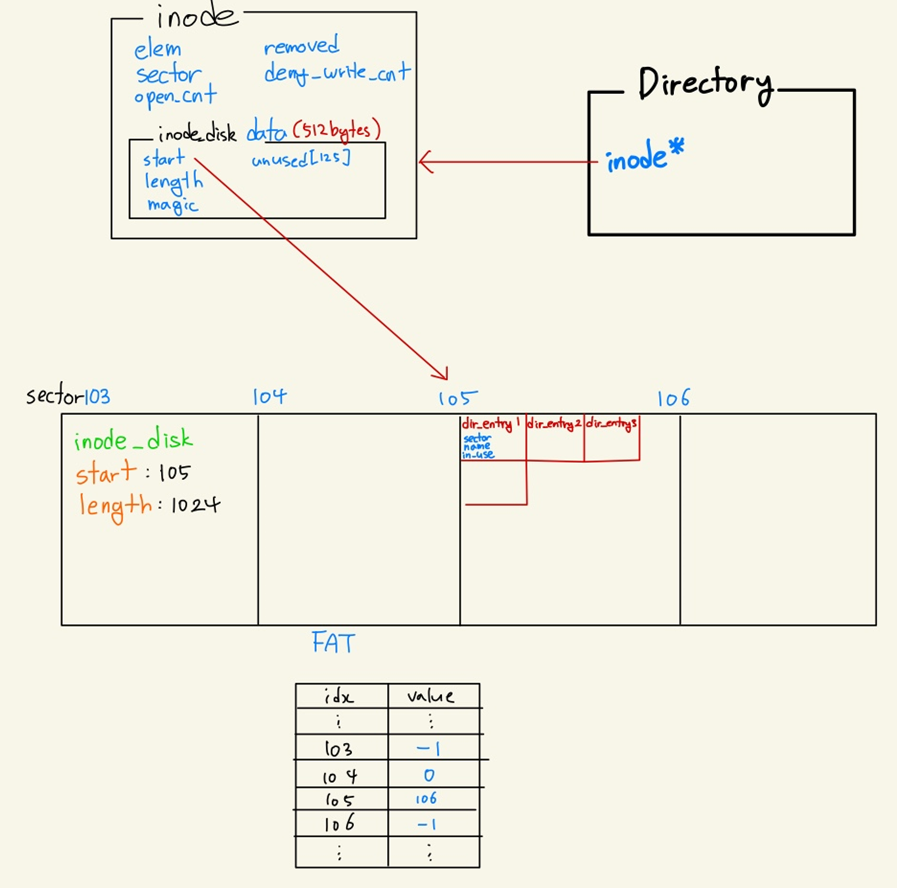
FAT 방식은 File Allocation Table이라는 표를 만들어서, 파일이 기록된 섹터들의 정보를 Chain 형태로 저장해놓은 것이다. 아래의 File D가 저장된 공간을 보면 4 - 9 - 10번 Sector에 순서대로 저장되어 있다. 이 정보를 FAT에 기록된 형태를 보면, FAT[4] = 9, FAT[9] = 10, FAT[10] = -1이 기록되어 있다. 4번 섹터의 다음 섹터는 9번 섹터이고, 9번 섹터의 다음 섹터는 10번 섹터이며, 10번 섹터가 해당 파일의 마지막 섹터라는 정보를 나타낸 것이다. (마지막 섹터에는 -1 혹은 구분할 수 있는 값을 넣어놓는다.)
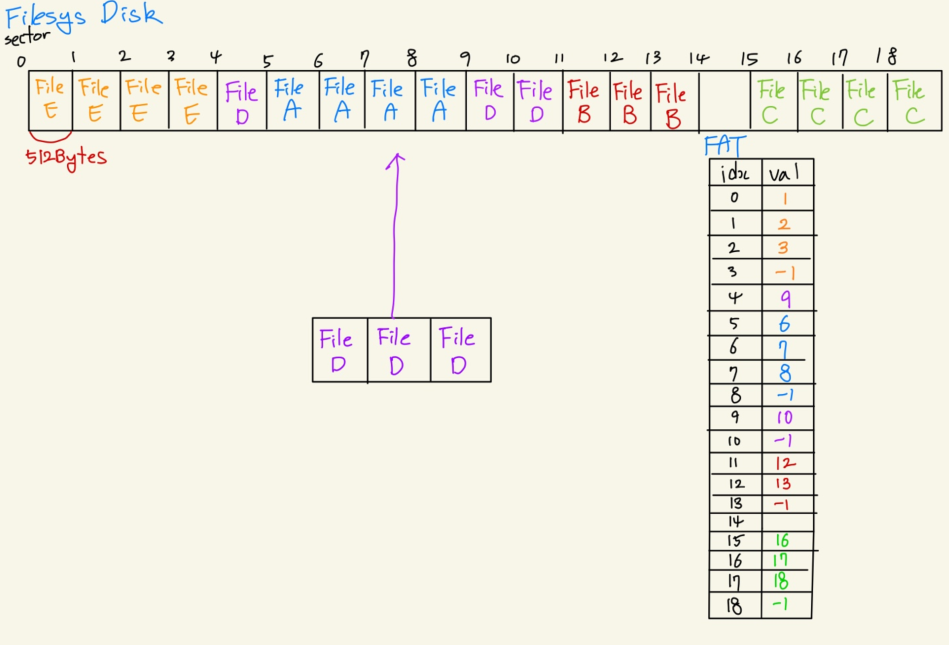
구현할 때 생각해야 할 점은 FAT 자체도 disk에 저장되어야 한다는 점이고, 이 부분은 침범되어서는 안된다는 것이다. 그래야 컴퓨터를 끄고 킬 때도 파일에 대한 정보가 남아있을 것이다.
지금은 FAT의 기본 단위(Cluster)가 1 sector와 같다고 가정했지만, 임의의 갯수의 sector를 하나의 cluster로 묶어서 관리하는 것도 가능하다.
2. Inode
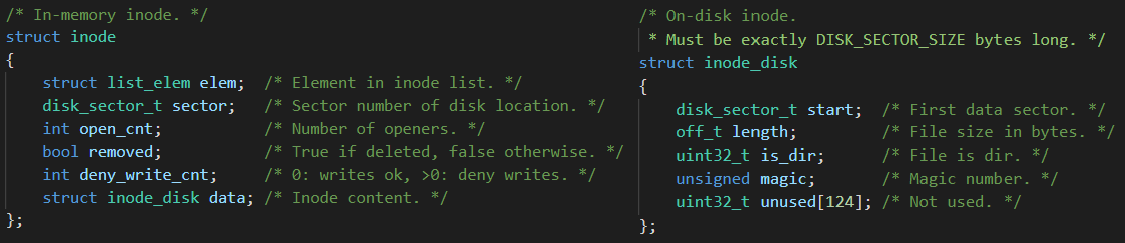
Inode란 파일이나 디렉토리에 대한 metadata를 가지고 있는 고유 식별자이다. 파일과 디렉토리는 모두 inode를 하나씩 가리키는 inode 포인터를 가지고 있다. inode 구조체는 파일이나 디렉토리를 열 때 발생하는 inode_open() 함수 실행 시에 생성되며, 열리지 않았을 때는 inode_disk인 상태로 Disk에 저장되어 있다. inode는 메타데이터 정보를 담고있는 512Byte의 inode_disk를 하나씩 가지고 있고, inode_disk는 실제 파일에 대한 메타데이터를 포함하고 있다. 실제 파일의 경우 아래와 같이 디스크에 저장되어있다.
* Metadata : 속성을 설명하는 정보
ex : 글의 길이, offset ...
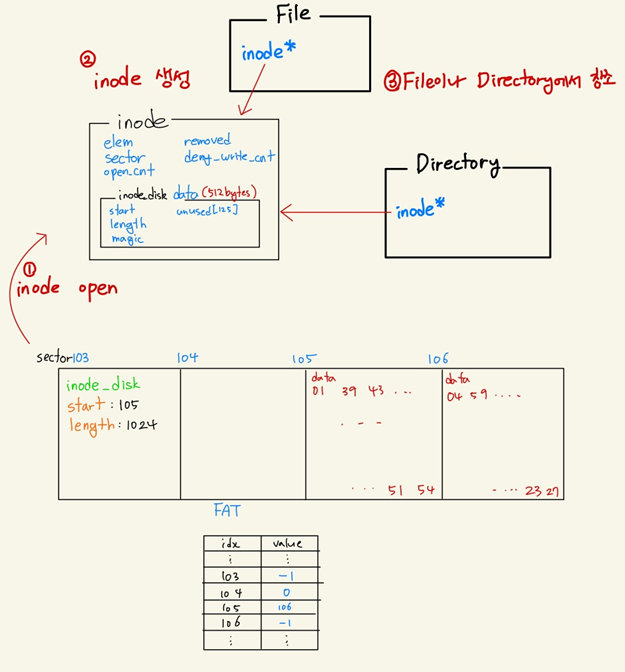
이제 inode 구조체의 원소들을 하나씩 살펴보자.
Inode
1. elem : inode를 생성하면 open_inodes라는 list에 추가해주기 위해 필요한 요소.
2. sector : inode_disk가 저장되어있는 disk의 sector를 나타낸다.
3. open_cnt : inode가 열려있으면 닫으면 안된다. 이를 관리해주기 위해 변수를 생성하여 카운팅한다.
4. removed : 삭제해도 되는지 여부를 저장한다. inode_remove()를 참조.
5. data : 디스크에 저장된 메타데이터 정보를 물리메모리에 올려놓은 것이다. 매번 disk에 참조할 수 없기 때문에 물리 메모리에 올려놓고 사용하며, 더이상 필요가 없어지면 inode_close()시에 다시 disk에 write back한다.
Inode Disk
1. start : 파일의 inode인 경우 파일의 실제 내용, 디렉토리의 inode인 경우 directory entry들이 저장되어 있는 disk의 sector 번호를 나타낸다.
2. length : 저장된 공간의 길이를 나타낸다(Sector 단위)
+ : 나머지 공간은 sector size인 512byte를 맞춰주기 위해 넣어둔 데이터이다. (Disk Write/Read 시에는 반드시 512byte 단위로 해야한다. 이 공간을 잘 활용할 수 있으면 좋다.
3. File
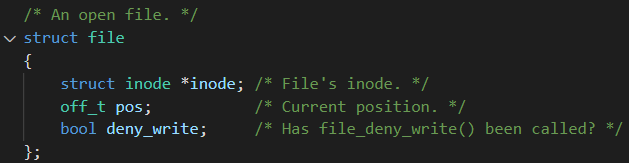
File Open을 하면 생성되는 파일 구조체이다. 코드 상의 inode는 File의 inode를 가리키고 있으며, 이 inode 안에는 File Data에 대한 Metadata가 저장되어있다(inode_disk). 하나하나 살펴보자.
1. inode : 파일 데이터에 대한 정보를 포함하고 있다.
2. pos : 파일을 읽거나 쓸 때 처음부터 다 읽거나 쓸 필요는 없다.
3. deny_write : 읽기 전용 파일을 나타내기 위해 사용하는 변수.

4. Directory
디렉토리도 파일이다. 자세히 보면 구조체 내에 inode가 동일하게 위치하고 있는 것도 볼 수 있다. 다만 File에 Data가 있었다면 Directory에는 directory_entry들이 있을 뿐이다. 기억해야 할 것은 directory를 조회하기 위해 dir 구조체를 따라 들어가면 inode가 있고, inode 안의 inode_disk에 기록된 sector를 따라가보면 dir_entry들이 기록되어있는 것이다. 내가 원하는 이름을 가진 dir_entry를 찾고, 이녀석이 가리키는 sector로 다시 가면 내가 원하는 데이터가 있을 것이다.
Directory, Directory_entry 구조체에 대해 알아보자.

Dir
1. inode : 하위 dir_entry들을 저장하고 있는 sector를 찾아가기 위해 이용한다.
2. pos : 어디까지 읽었는지 확인한다.(readdir()구현 시 사용)
Dir Entry
1. inode_sector : dir_entry의 정보를 담고있는 sector를 가리킨다.
2. name : 파일이나 디렉토리의 이름이다.
3. in_use : lookup 할 때 사용할 정보이다. 이 위치에 dir_entry가 저장되어있는지에 대한 정보를 나타낸다.
Project 4 - 구현
0. FAT
1) fat.c에 기본적인 내용(boot 시 fat를 load하고 종료 시 fat를 write back하는 기능)은 구현되어있다.
2) 우리가 해야할 일은 fat 테이블을 업데이트하고, 컴퓨터를 끄고 키더라도 동일한 위치에 저장되어있도록 보장하는 것이다.
3) Root Directory는 format할 때 만들어줘야 한다.
4) Cluster to sector 함수를 잘 생각하고 만들어야 한다. fat table도 disk에 저장되어야 한다는 점을 꼭 기억하자. 이부분을 아예 없다고 생각하고 Cluster to sector을 만들 것인지, 아니면 있다고 생각하되 데이터가 이미 기록되어있음을 File Allocation Table에 기록할 것인지를 선택해야한다. Sector가 들어가야 하는 위치에 Cluster가 인자로 들어가거나, 반대로 된 경우가 없는지 반드시 체크하자.
1. Extensible Files
1) FAT를 구현했다면 이건 쉽다. inode_create이나 Write/Read시에 내가 잘 만들어놓은 Chain을 따라가게 하면 된다. 만약 File length를 늘린다고 하면, 새로운 chain을 하나 추가하여 기록한다.
2) File length가 늘어난다고 하면 inode_disk에 이 data를 업데이트해줘야 하며, sector_size와 file_length는 다르다는 점을 인지하자.
3) inode_disk는 data의 길이에 포함되지 않는다.
2. Subdirectories
1) 입력을 받은 뒤 parsing하여 효율적으로 인자를 전달하는 것이 생각보다 까다롭다. 예외처리와의 싸움일 것이다. 인자가 비어있거나, 존재하지 않거나, 지우면 안되거나 등등을 고려해야 한다.
2) .과 ..은 기본적으로 directory에 추가해주는 것이 좋다.
3) 파일을 열었다면, 반드시 잘 닫아줘야 한다. open_cnt 때문인데, 일반적으로 open_cnt가 0일 때 inode의 사용이 끝났음을 인지하고 disk에 write back해주기 때문이다. 그렇다면 open_cnt가 언제 증가하고 언제 감소하는지에 대해 이해하고 있어야 한다. inode_open(dir_open이 아님)이나 reopen시에 증가하고, inode_close 시에 감소한다. inode_open함수는 어디서 사용하는지 확인해보자.
4) directory인지, file인지 확인이 필요할 때가 있다. Syscall마다 이를 구분할 필요가 있는 경우에는 처리해준다.
5) directory도 open할 수 있다. open된 directory는 제거하면 안된다.
3. Persistence
1) 위의 과정을 제대로 했다면 종료 후 다시 Booting을 하더라도 데이터가 잘 기록되어있어야 한다.
2) 위에서 말했던 open_cnt를 잘 고려하지 않았거나, root directory를 boot 시마다 갱신해주는 것은 아닌지 확인해보자
Project 4 - 후기
드디어 192개의 모든 Test를 안정적으로 통과하는 것을 확인했다. 길고 길었던 Pintos, 잠도 잘 못자는 경우가 다반사였지만, 많은 것을 느낄 수 있었던 기간이었다. Linux에 대한 기본적인 이해도 할 수 있었고, 아예 모르는 것에 대한 두려움을 많이 줄일 수 있었다. Pintos를 처음 시작하는 사람이라면, 처음에 진짜 아무것도 몰라서 막막하더라도 조금씩 이해하다보면 끝낼 수 있다고 말해주고 싶다.
Goodbye PINTOS ~
'SW사관학교 정글 > 프로젝트' 카테고리의 다른 글
| PINTOS (3) Virtual Memory (0) | 2021.02.19 |
|---|---|
| B-Tree 삭제 (0) | 2021.02.15 |
| B-Tree 생성, 삽입 (0) | 2021.02.15 |
| Pintos Project2 - User Programming (0) | 2021.02.15 |
| PINTOS Project1 - Threads (0) | 2021.01.28 |




















