이제 드디어 패스트캠퍼스의 데이터 분석 패키지의 마지막을 달리고 있습니다!
이번주에는 주어진 영화 관련 데이터와 고속도로 통행 관련 데이터를 분석해보는 시간입니다.
1. 박스 오피스 데이터 요약
주어진 데이터는 영화진흥위원회(http://www.kobis.or.kr)에서 배포하는 관객수 기준 역대 박스 오피스 상위 200개에 대한 정보입니다.
주어진 데이터의 구성은 아래와 같습니다.

Columns : 영화명, 개봉일, 매출액, 관객수, 스크린수, 상영횟수, 대표국적
Rows : 200개의 영화
이 데이터를 예제들을 통해 아래와 같이 간단히 요약해보았습니다.
##0 데이터 불러오기
library(openxlsx)
movies = read.xlsx('data/movies.xlsx')
##1 : head( ), tail( ), names( ) 함수에 데이터를 넣어서 실행하기
head(movies)
tail(movies)
names(movies)
##2 : $를 활용해서 변수를 선택하여 매출액, 관객수, 상영횟수의 최댓값 계산하기
max(movies$매출액)
max(movies$관객수)
max(movies$상영횟수)
## (예제) 스크린수의 평균값 계산하기
mean(movies$스크린수)
##3 which.max( )로 매출액 최대, 관객수 최대 영화 확인하기
## 최소 스크린수 영화 확인하기
which.min(movies$스크린수)
movies[60, ]
movies[which.max(movies$관객수),]
movies[which.max(movies$매출액),]
##4 관객수의 히스토그램과 상자그림 그리기
hist(movies$관객수)
boxplot(movies$관객수)
##5 관객수를 상영횟수로 나눠 상영횟수당 관객수가 가장 많은 영화 찾기
movies[which.max(movies$관객수 / movies$상영횟수),]
2. 고속도로 통행 데이터 요약
주어진 데이터는 2018년 12월의 고속도로 통행 데이터입니다.
고속도로 공공데이터 포털(http://data.ex.co.kr)에서 주어진 데이터를 활용합니다.
주어진 데이터의 구성은 아래와 같습니다.
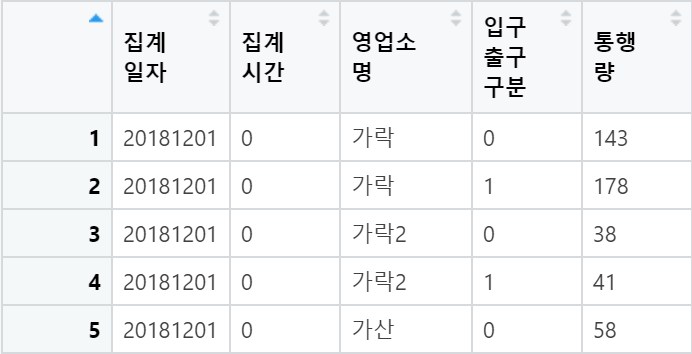
Columns : 집계 일자, 집계 시간, 영업소 명, 입구출구 구분, 통행량
Rows : 585064개의 출입 데이터
이 데이터를 예제들을 통해 아래와 같이 간단히 요약해보았습니다.
##0 데이터 불러오기
# 데이터 불러오기
highway = read.csv('data/highway_1812.csv', fileEncoding='UTF-8')
highway
# 집계일자를 날짜 형식으로 변환
highway$집계일자 = strptime(highway$집계일자, format='%Y%m%d')
# 요일 변수 추가하기
highway$요일 = weekdays(highway$집계일자)
highway
##1 변수이름, 관측치 샘플 확인하기
names(highway)
##2 subset( )으로 토요일 데이터만 모아서
## highway_sat 로 저장하기
highway_sat = subset(highway, highway$요일 == '토요일')
highway_sat
##3 영업소명 '통영' 혹은 '북통영' 이면서 요일 기준 '토요일', '일요일'인 데이터만 모아서 ty_weekend 로 저장하기
ty_weekend = subset(highway, highway$요일 %in% c('토요일', '일요일') & highway$영업소명 %in% c('통영', '북통영'))
## (예제) %in%의 활용
subset(highway, 영업소명 %in% c('서울(특)', '동서울'))
## (예제) &를 활용한 조건 결합
(1:5 >= 3) & (1:5 <= 3)
##4 aggregate( )로 요일별 통행량 합계 계산하기
aggregate(highway$통행량, by = list(highway$요일), FUN = sum)
##5 3에서 만든 ty_weekend로 집계시간별 통행량 합계를 계산하기
aggregate(ty_weekend$통행량, by = (list(ty_weekend$집계시간)), FUN = sum)
9주차 후기를 마치겠습니다. 이상 끝-!
'데이터 사이언스 > 패스트캠퍼스' 카테고리의 다른 글
| [패스트캠퍼스 수강후기] 데이터 분석 입문 올인원 패키지 _ 수강후기 (0) | 2019.11.17 |
|---|---|
| [패스트캠퍼스 학습일지] 데이터분석 올인원 패키지 _ 10주차 : 혼자 해보는 데이터 분석_Insurance (0) | 2019.11.12 |
| [패스트캠퍼스 학습일지] 데이터분석 올인원 패키지 _ 8주차 : 고등학교 수학으로 이해하는 통계와 데이터 분석 (0) | 2019.11.02 |
| [패스트캠퍼스 학습일지] 데이터분석 올인원 패키지 _ 7주차 : 중학교 수학으로 이해하는 통계와 데이터 분석 (0) | 2019.10.22 |
| [패스트캠퍼스 학습일지] 데이터분석 올인원 패키지 _ 6주차 : 데이터 분석가 (0) | 2019.10.20 |