그래프란 객체 간에 짝을 이루는 관계를 정점(Vertice)와 간선(Edge)으로 나타내는 수학구조이다.
예를 들면, 아래와 같이 대한민국의 도시들의 고속도로 연결관계를 그래프 구조로 나타낼 수 있다.
(임의로 그린 것입니다.)
그래프는 아래와 같은 수식으로 나타낸다.
G = ( V , E )
V는 정점(Vertice), E는 간선(Edge)를 나타낸다. 위 그래프는 7개의 정점과 9개의 간선을 가진 그래프이다.
이제 그래프 구조를 자료구조로 나타내보자.
그래프를 표현하는 방법으로는 인접 행렬 표현법, 인접 리스트 표현법이 있다.
인접 행렬 표현법
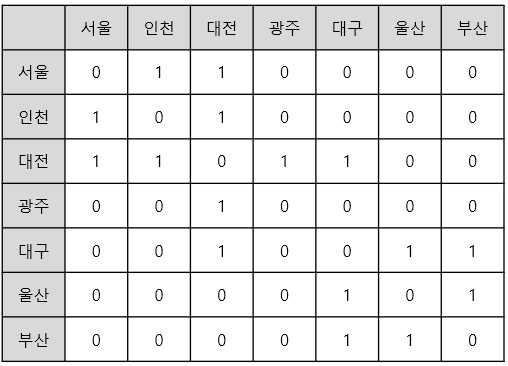
그래프의 연결 정보를 행렬로 저장하는 방법이다. 아래와 같이 세로축, 가로축에 각 도시 이름을 기록하고, 교차하는 곳에 도시를 연결하는 고속도로의 존재 여부를 표기한다. 고속도로가 있다면 1, 없다면 0을 기록하면 된다. 행렬의 크기는 정점(V)의 제곱이 된다. 따라서 간선이 많은(=높은 밀도의) 그래프의 표현 시 사용된다.
* 위와 같이 간선의 방향성이 없는 경우를 무방향 그래프라고 한다. 무방향 그래프는 인접 행렬로 표현했을 때 대칭이 되므로, 반만 저장하여 메모리 효율을 높일 수 있다.
인접 리스트 표현법
그래프의 연결 정보를 리스트로 저장하는 방식이다. 도시 길이만큼의 배열을 만들고, 각 도시에 연결된 도시들을 리스트로 저장한다. 이때 저장되는 도시들의 수는 (간선의 총 개수 * 2) 이다. 즉, 2 * E만큼의 메모리를 사용한다. 따라서 정점의 개수에 비해 간선의 개수가 적은(=낮은 밀도의) 그래프의 표현 시 사용된다.
각 리스트에 저장되는 순서는 알고리즘 구조에 따라 다르다.
* 인접 리스트 표현은 무방향/방향 그래프 모두 메모리 사용이 동일하다.
이렇게 저장된 데이터를 사용하여 원하는 최댓값/최소값을 구하는 데 사용되는 알고리즘이 BFS, DFS이다. 해당 알고리즘에 대한 정보는 아래 글에 있다.
탑들이 일렬로 서있다. 각 탑의 꼭대기에서 왼쪽을 보았을 때, 높이가 같거나 높은 가장 가까운 탑을 출력하는 문제이다. 만약 없다면, 0을 출력한다.
* 힌트
1. 스택을 활용한다.
2. i번째 탑의 높이보다 i+1번째 탑의 높이가 높다면, i번째 탑은 i+1번 이후 탑들의 신호를 수신하지 못한다.
* 풀이
스택을 생성하고, 신호를 수신할 가능성이 있는 탑들은 스택에 추가한다.
1. 앞에서부터 순차적으로 탐색한다. 0<=i<len(tower_list)
2. 스택이 비었을 때는 수신 가능한 탑이 없다는 뜻이므로 0을 출력하고 스택에 i번째 탑의 [높이, index]를 추가한다.
3. 스택이 비지 않았다면, 스택에 들어있는 탑들에 대하여 높이가 현재 탑의 높이보다 같거나 높은지 비교한다.(현재 탑의 신호를 수신할 수 있는지 확인)
4. 현재 탑보다 높이가 낮은 것은 스택에서 pop하고, 높은 것이 있다면 해당 탑의 Index를 출력하고 스택의 현재 탑을 추가한다. 스택 탐색을 멈춘다.
5. 1~4번을 tower_list의 끝까지 반복한다.
* 예제
탑들이 위 그림과 같이 주어져 있다.
각 탑들의 신호를 몇번째 탑에서 수신하는지 확인해본다.
첫번째 탑의 신호 : 받을 수 있는 탑이 없다. → 0을 출력
두번째 탑의 신호 : 받을 수 있는 탑이 없다.→ 0을 출력
세번째 탑의 신호 : 두번째 탑이 수신한다. → 2을 출력
네번째 탑의 신호 : 두번째 탑이 수신한다. → 2을 출력
다섯번째 탑의 신호 : 네번째 탑이 수신한다 → 4을 출력
정답 : 0 0 2 2 4
그럼 위의 예제를 실제 코드로 테스트해본다.
* Index에 주의 : 첫번째 탑의 Index 0*
tower_list = [6, 9, 5, 7, 4]
[1] 첫번째 탑 : index = 0, 탑의 높이 = 6, 스택 = []
1) 스택이 비어 있으므로, 스택에 [6(탑의 높이), 0(탑의 Index)]를 추가한다.
2) 스택이 비어있다는 뜻은, index 0번 탑의 신호를 수신할 수 있는 탑이 없다는 것을 의미하므로 0을 출력한다.
output = '0'
[2] 두번째 탑 : index = 1, 탑의 높이 = 9 스택 = [ [6,0] ]
1) 스택이 비지 않았으므로, 비교를 시작한다.
2) 스택의 첫번째 원소 : [6,0]
현재 탑의 높이 : 9 > 6 이므로 첫번째 원소를 pop한다.
3) 스택이 비었으므로 두번째 탑의 신호를 수신할 수 있는 탑은 없다.
현재 탑의 높이와 인덱스를 스택에 추가한다.
output = '0 0'
[3] 세번째 탑 : index = 2, 탑의 높이 = 5 스택 = [ [9,1] ]
1) 스택이 비지 않았으므로, 비교를 시작한다.
2) 스택의 첫번째 원소 : [9,1]
현재 탑의 높이 : 5 < 9 이므로 해당 탑에서 세번째 탑의 신호를 수신한다.
높이 9인 탑의 index +1(2)를 출력하고, 현재 탑의 높이와 인덱스 [5,2]를 스택에 추가한다.
output = '0 0 2'
[4] 네번째 탑 : index = 3, 탑의 높이 = 7, 스택 = [ [9,1], [5,2] ]
1)스택이 비지 않았으므로, 비교를 시작한다. (스택의 오른쪽부터 탐색한다. 이는 가장 가까운 탑부터 탐색한다는 의미이다.)
2) 스택의 첫번째 원소 : [5,2]
현재 탑의 높이 : 7 > 5이므로, 해당 탑을 pop하고 다음 탑과 비교한다.
3) 스택의 두번째 원소 : [9,1]
현재 탑의 높이 : 7 < 9이므로, 해당 탑에서 네번째 탑의 신호를 수신한다.
높이가 9인 탑의 index + 1(2)을 출력하고, 현재 탑의 높이와 인덱스 [7,3]을 스택에 추가한다.
output = '0 0 2 2'
[4] 다섯번째 탑 : index = 4, 탑의 높이 = 4, 스택 = [ [9,1], [7,3] ]
1) 스택이 비지 않았으므로, 비교를 시작한다.
2) 스택의 첫번째 원소 : [7,3]
현재 탑의 높이 : 4 < 7이므로, 해당 탑에서 다섯번째 탑의 신호를 수신한다.
높이가 7인 탑의 index + 1(4)를 출력하고 현재 탑의 높이와 인덱스 [4,4]를 스택에 추가한다.
최종 output = '0 0 2 2 4'
스택 : [ [9,1], [7,3], [4,4] ]
import sys
r = sys.stdin.readline
# 입력 받기
n = int(r())
t_list = list(map(int, r().split()))
answer = []
stk = []
for i in range(n):
h = t_list[i]
if stk:
#print(stk)
while stk:
if stk[-1][0] < h :
stk.pop()
if not stk:
print(0, end=' ')
elif stk[-1][0] > h:
print(stk[-1][1]+1, end=' ')
break
else :
print(stk[-1][1]+1, end=' ')
stk.pop()
break
stk.append([h, i])
else:
print(0, end=' ')
stk.append([h,i])
괄호의 조합들을 입력받았을 때, 쌍이 제대로 맞으면 'YES', 아니면 'NO를 출력하는 문제이다.
* 힌트
1. 스택의 개념을 사용한다.
* 풀이
end = 0
1. 입력을 받아 차례로 스택에 넣는다.
2. 스택의 원소들을 하나씩 pop하며 아래 조건에 따른다.
1) pop한 원소 = ')'
: end + 1 을 해준다.
2) pop한 원소 = '('
: end - 1을 해준다.
3) end <0일 경우 break
3. for문이 끝났을 때 end가 0인지 확인한 후 0이면 'YES', 아니면 'NO'를 출력한다.
해당 문제는 알고리즘 문제에 자주 등장하는데, 스택의 개념을 활용해서 풀 수 있다는 것을 처음 알았다.
import sys
r = sys.stdin.readline
n = int(r())
# (이면 end - 1
# )이면 end + 1
# 두번째 for문 내에서 end 가 0보다 작아지면 No를 출력하고, 마지막에 end가 0인지 확인한다.
for i in range(n):
string = list(r().strip())
end = 0
for i in range(len(string)):
x = string.pop()
if x == ')':
end += 1
else:
end -= 1
if end <0:
break
if end !=0:
print('NO')
else:
print('YES')
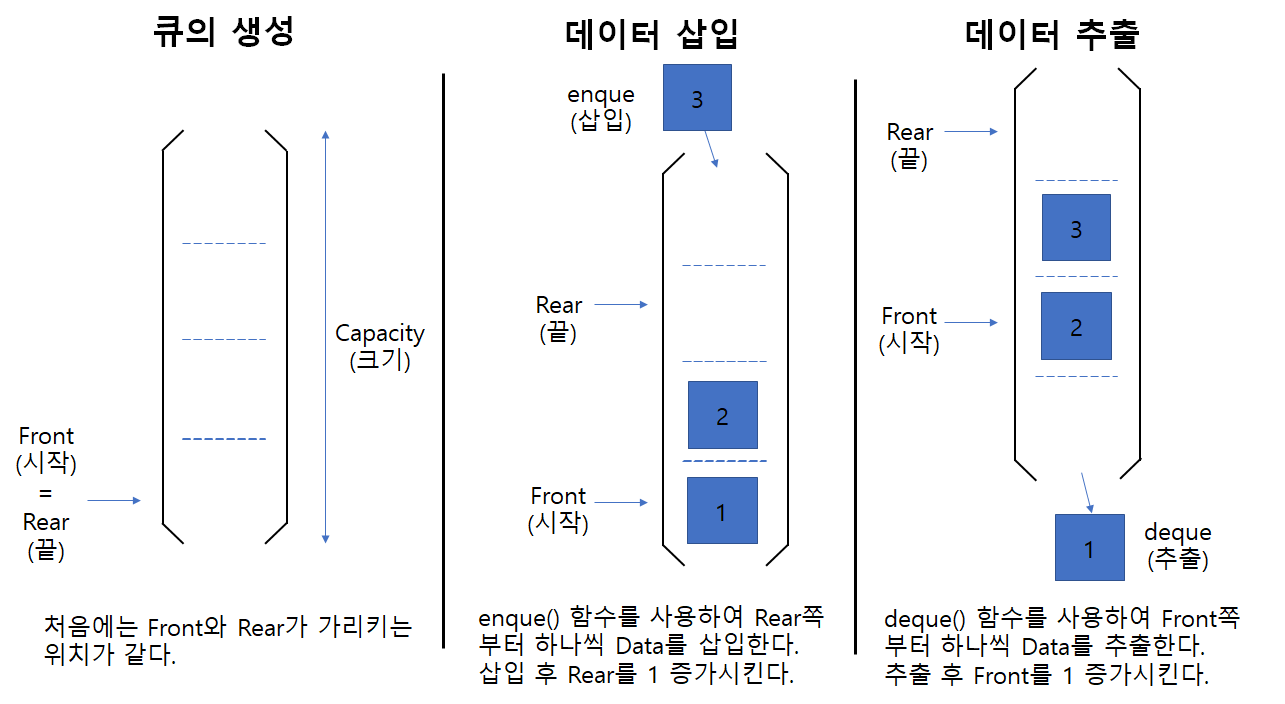
아래의 맨 왼쪽과 같이 빈 탄창과 총알 4개가 있다고 하자. 총알 4개를 1번부터 순서대로 넣으면 가운데 그림처럼 될 것이다. 이후 총을 쏘기 시작하면 맨 마지막에 넣은 4번 총알부터 발사가 될 것이다.
(탄창 = Stack, 총알 = Data) 과 같이 생각하면 된다. 스택에 데이터를 넣는 과정은 탄창에 총알을 넣는 과정과 동일하며, 스택에서 데이터를 빼는 과정은 탄창에서 총알이 발사되는 과정과 동일하다.
스택에 데이터를 넣는 행위를 Push, 스택에서 데이터를 빼는 행위는 Pull이라고 부른다. 4개의 데이터를 스택에 넣고 빼는 과정을 생각해보면, 가장 먼저 넣은 데이터(1번)이 가장 마지막에 나오는 것을 알 수 있다. 이런 데이터 구조를 FIFO(First In Last Out, = 선입후출)이라고 부른다.
스택은 크기 제한(Top = capacity)을 가지고 있으며, 데이터는 맨 아래(Bottom)부터 꼭대기까지 하나씩 순차적으로 들어간다. 데이터를 꺼낼 때는 맨 위에서부터(가장 최근에 넣은 것부터) 하나씩 뺄 수 있다. 이제 해당 자료구조를 파이썬으로 구현하기 위한 함수, 변수들을 생각해보자.
* 변수
1. 스택 포인터(ptr)
: 현재 스택에 데이터가 어디까지 쌓여있는지 나타내는 포인터.
2. 크기(capacity)
: 스택의 크기를 나타내는 변수. 스택 생성 시 지정해준다.
* 함수
1. __init__() : 변수 초기화
2. push() : 스택에 데이터를 한개 삽입한다.
3. pop() : 스택에서 데이터를 한개 꺼낸다.
4. __len__() : 현재 쌓여있는 데이터의 크기를 반환한다.
5. is_empty() : 스택의 empty 여부를 확인한다.
6. is_full() : 스택이 가득 찼는지 확인한다.
7. peek() : 가장 최근에 쌓인 데이터를 읽는다.
8. clear() : 스택을 초기화한다.
9. find() : 스택 내에서 특정 값을 찾는다.
10. count() : stack에 있는 특정 값의 개수를 찾는다.
11. contains() : 특정 값을 포함하고 있는지 확인한다.
12. dump() : 스택 내의 모든 데이터를 출력한다.
구현은 아래와 같다. 스택 포인터(ptr)이 작동하는 방식을 잘 봐야 한다.
1. 스택 포인터는 항상 빈 공간을 가리키고 있다.
2. 포인터의 위치만을 수정하여 스택초기화, 데이터 제거가 가능하다.
#Fixed스택 직접 구현해보기
from typing import Any
class FixedStack:
##Stack Pointer는 미리 다음 빈 공간을 가리키고 있다.
class Empty(Exception):
pass
class Full(Exception):
pass
def __init__(self , c : int) -> None:
## 변수 초기화 함수.
## stack의 크기를 생성 시 전달받는다.
self.ptr = 0
self.capacity = c
self.stk = [None] * c
def __len__(self) -> int:
## Stack의 길이를 반환하는 함수
## ptr은 다음 빈 공간을 가리키고 있기 때문에 길이와 같다.
return self.ptr
def is_empty(self) -> bool:
## Stack이 비었는지 확인하는 함수
return self.ptr <= 0
def is_full(self) -> bool:
## Stack이 가득 찼는지 확인하는 함수
return self.ptr >= self.capacity
def push(self, data: int) -> None:
if self.is_full():
raise FixedStack.Full
self.stk[self.ptr] = data
self.ptr += 1
def pop(self) -> any:
## Stack의 가장 바깥에 쌓여있는 데이터를 Stack에서 빼는 함수.
## 비었는지 확인하고 data를 return한다. 이 때 ptr만 하나 줄여주면 된다.
if self.is_empty():
raise FixedStack.Empty
self.ptr -= 1
return self.stk[self.ptr]
def peek(self):
## 가장 바깥에 쌓여있는 데이터를 읽어오는 함수
## 비어있는지 확인 후 data를 return한다.
if self.is_empty():
raise FixedStack.Empty
return self.stk[self.ptr-1]
def clear(self):
## Stack을 초기화하는 함수
self.ptr = 0
def find(self, value: Any) -> Any:
## 전달받은 값을 찾는 함수.
## 찾으면 index를 반환한다.
for i in range(self.ptr - 1, -1, -1):
if self.stk[i] == value:
return i
return -1
def count(self, value : Any) -> int:
## Stack 안에 찾고자 하는 값이 몇개인지 찾는다.
count = 0
for i in range(self.ptr):
if self.stk[i] == value:
count += 1
return count
def __contains__(self, value: Any) -> bool:
## Stack이 특정 값을 포함하고 있는지 확인하는 함수
return self.count(value)
def dump(self) -> None:
## 데이터를 바닥부터 꼭대기까지 출력한다.
## ptr까지 출력해야 하는 이유는 그 뒤에 삭제하지 않고 남은 데이터가 있을 수도 있기 때문!
if self.is_empty():
raise FixedStack.Empty
else:
print(self.stk[:self.ptr])
인수인계, 이사, 인간관계 정리를 하다보니 눈깜짝할새에 3주가 지나가버렸고, 새로운 시작을 위한 첫 발걸음을 떼는 날이 다가왔다. 회사 생활을 하며 불만이 많았지만, 마지막 퇴근 때 눈물이 찔끔 났던걸 생각해보면 미운 정이 들었나보다. 막상 모든걸 새롭게 시작하려니 살짝 두렵기도 한 지금, 초심을 잃지 않고자 내 각오를 적어본다.
지나온 삶을 돌아보면, 언제나 안정적인 길을 그럭저럭 잘 걸어왔던 것 같다. 정규 교육을 이수하고 대학교에 진학하여, 졸업 뒤 취직. 이대로 안정적인 길을 가다보면 회사에서 퇴직을 했을테고, 퇴직 후에도 삶에 대해 고뇌했겠지만 가족들과의 행복을 위안삼으며 여생을 살았을 것 같다. 하지만 나는 늘 안정적인 길을 걸어오면서 의문이 가득했다. '나는 뭘 좋아하지?', '이렇게 사는 것이 행복한 것인가?' 같은 것들이다. 물론 요즘은 잊고 사는게 더 나은 질문들도 있다고 생각하지만, 이런 질문들에 대한 고뇌가 나를 여기로 이끌었음을 부정할 수 없다.
지금까지 파악한 나의 지향점은 '기술을 통해 세상의 좋은 변화에 기여하는 사람'이다. (이 간절함이 극에 달하면 창업의 길로 뛰어들겠지만, 내가 그 지경까지 도달할 수 있을지는 의문이 든다.) 어떻게 목표를 이룰 수 있을까 고민하다가, '더 많은 기여를 하려면 뛰어난 사람이 되어야 하고, 뛰어난 사람이 되려면 열심히 일을 통해 배워야 하며, 열심히 하려면 자기가 좋아하는 일이여야 한다.' 라는 생각이 들어 회사를 뛰쳐나왔다.
시작으로부터 일주일이 지난 지금, 밤이라도 새서 했어야 할 과제들을 조금씩 미루고 있는 내 자신을 보며 의구심이 드는 것도 사실이다. 하지만 믿어야 한다. 나를 믿고 조금 더 채찍질하며 남은 기간동안 열심히 달려서, SW 엔지니어로서 훌륭한 소프트 랜딩을 할 것이다. 열심히 하고 난 이후의 일은 그때 가서 생각하고, 우선 내 인생을 바꿀 수 있는 17주가 내 앞에 주어졌다. 열심히 달려서 5개월 뒤에 축배를 들 수 있기를.